Master Retrieval-Augmented Generation—end ChatGPT hallucinations, access live data, and see why 80% of enterprises back this $40 billion AI upgrade with this guide
Nate
Imagine you meet someone brilliant—someone who seems to know absolutely everything. Every answer they give feels sharp, insightful, even groundbreaking. Now, picture this person having one fatal flaw: every so often, they confidently state something that’s totally wrong. Not just wrong, mind you, but spectacularly incorrect—like insisting that Abraham Lincoln was a professional skateboarder. Welcome to the current state of Large Language Models (LLMs).
As fascinating and powerful as AI systems like ChatGPT and Claude have become, they still possess what I affectionately (and sometimes frustratingly) call a “frozen brain problem.” Their knowledge is permanently stuck at their last training cutoff, causing them to occasionally hallucinate answers—AI jargon for confidently stating nonsense. In my more forgiving moments, I compare it to asking a very smart student to ace an exam without any notes: impressive, yes, but prone to error and entirely reliant on memory.
That’s where Retrieval-Augmented Generation, or RAG, enters the chat. RAG fundamentally reshapes what we thought possible from AI by handing these brilliant-but-flawed models a crucial upgrade: an external, dynamic memory. Imagine giving our hypothetical brilliant person access to an extensive, always-up-to-date digital library—now every answer can be checked, validated, and supported with actual data. It’s like turning that closed-book exam into an open-book test, enabling real-time, accurate, and trustworthy answers.
The stakes couldn’t be higher. We’re moving quickly into a future where businesses, hospitals, law firms, and schools increasingly rely on AI to handle complex information retrieval and decision-making tasks. According to recent market analyses, this isn’t a niche upgrade—it’s a seismic shift expected to catapult the RAG market from $1.96 billion in 2025 to over $40 billion by 2035. Companies who fail to embrace RAG risk becoming like video rental stores in the Netflix era: quaint, nostalgic, but rapidly obsolete.
I’ve spent considerable time sifting through the noise, experimenting, succeeding, and occasionally stumbling with RAG. This document you’re holding—or, more realistically, scrolling through—is the distilled result: a 53-page guide that’s comprehensive, nuanced, and occasionally humorous (I promise, there’s levity amidst the deep dives into cosine similarity and chunking strategies). Whether you’re a curious novice or a seasoned practitioner, there’s gold here for everyone.
Inside this guide, we’ll demystify exactly how RAG works—retrieval, embedding, generation, chunking, and all—using analogies clear enough for dinner party conversations and precise enough for your next team meeting. We’ll explore advanced techniques, including hybrid searches and multi-modal retrieval, to ensure you don’t just understand RAG—you master it. We’ll even examine some cautionary tales from companies who jumped in headfirst without checking the depth (spoiler: they regret it).
Why should you read this? Because memory matters. In AI, memory isn’t a nice-to-have feature; it’s the essential backbone that transforms impressive parlor tricks into reliable, transformative technology. If you’re investing in AI, building products, or even just navigating an AI-driven world, understanding RAG isn’t optional—it’s critical.
So, pour a coffee, settle in, and let’s tackle this together. You’re about to gain the keys to AI’s memory revolution, ensuring your AI doesn’t just sound brilliant but actually knows its stuff. Welcome to your next-level guide on Retrieval-Augmented Generation: AI’s long-awaited memory upgrade.
Subscribers get all these pieces!
Subscribed
From 0 to 5K: The Complete Simplified Guide to RAG (Retrieval-Augmented Generation)
=========================================================================================
Imagine if ChatGPT had perfect memory – never hallucinating, and able to tap your company’s entire knowledge base in real time. That’s the promise of Retrieval-Augmented Generation (RAG), and it’s changing everything about how we build with AI. In this guide, we’ll demystify RAG from the ground up, transforming complex concepts into an engaging, accessible journey for AI enthusiasts.
Why RAG Changes Everything
Picture this: you ask your AI assistant a question, and it instantly pulls up exactly the right facts from your company docs, giving a confident answer with references. No more “hallucinated” nonsense – just accurate, up-to-date info. This isn’t sci-fi; it’s RAG, and it’s big. Analysts project the RAG market to soar from about $1.96 billion in 2025 to over $40 billion by 2035. Companies are betting big on RAG because it tackles AI’s biggest weak spots (memory and truthfulness) head-on.
Did you know? LinkedIn applied RAG (with a knowledge graph twist) to their customer support and slashed median ticket resolution time by 28.6%. And they’re not alone. Roughly 80% of enterprises are now using RAG approaches (retrieval) over fine-tuning their models – a massive shift in strategy. Why? Because RAG gives AI real-time data access, and that’s gold. One survey found nearly 73% of companies are engaged with AI in some form , and providing those AI systems with current, relevant data is the new race. In other words, the companies winning in 2025 aren’t the ones with the biggest model – they’re the ones whose AI knows their business inside and out.
So buckle up. By the end of this guide, you’ll see why RAG is the hot topic (a $1.96B opportunity and growing ), how it’s delivering “wow moments” like LinkedIn’s support success, and why 73%+ of orgs are scrambling to give their AI a real-time knowledge upgrade. RAG changes everything by making AI both smart and knowledgeable – and today, we’ll show you how to go from 0 to RAG hero in an approachable, step-by-step narrative.
RAG Basics: Your AI Gets a Research Assistant
If a large language model (LLM) is like a brilliant student who studied everything up until 2023, then RAG gives that student a real-time library card. It’s like letting your AI take an open-book exam instead of relying on memory alone. How does that work? Think of RAG as giving your AI a research assistant: when asked a question, the AI can Retrieve relevant info from a knowledge source, Embed that info into a form it understands, and then Generate a final answer using both its built-in knowledge and the retrieved facts.
Analogy alert: LLMs are like students; RAG lets them bring notes. As one engineer quipped, “LLMs don’t know – they predict. Their memory is frozen. That’s where RAG changes the game. It’s like giving the model an open-book test: it still has to reason, but now it gets to reference something real”. In practice, that means when an LLM gets a query, a RAG system will first fetch relevant text (from your documents, websites, etc.), and supply those facts to the model so it can formulate a grounded answer. The magic three-part process is:
- Retrieval: Take the user’s question and search a knowledge source for relevant info (just like Googling or querying a database).
- Embedding: Behind the scenes, both the question and documents are converted into numerical embeddings – basically, turning words into vectors (imagine coordinates in a 1536-dimensional space for OpenAI’s ada-002 model ) so that semantic similarity can be computed.
- Generation: The LLM receives the question plus the retrieved context and generates a final answer, augmented by these real-time facts.
Traditional LLMs have a fixed knowledge cutoff and often bluff when asked something outside their training. RAG makes the LLM’s knowledge dynamic and verifiable. It’s the difference between a student taking a closed-book test (relying on possibly outdated memory) vs. an open-book test with the latest textbook in hand. For example, without RAG, an LLM is stuck with whatever it learned in training – ask it about something it never saw, and it might just make up an answer. With RAG, we first retrieve the latest relevant info and feed it in, so the model’s answer can cite real data.
Here’s a simple diagram of a RAG workflow, which shows how a query flows through retrieval into generation:
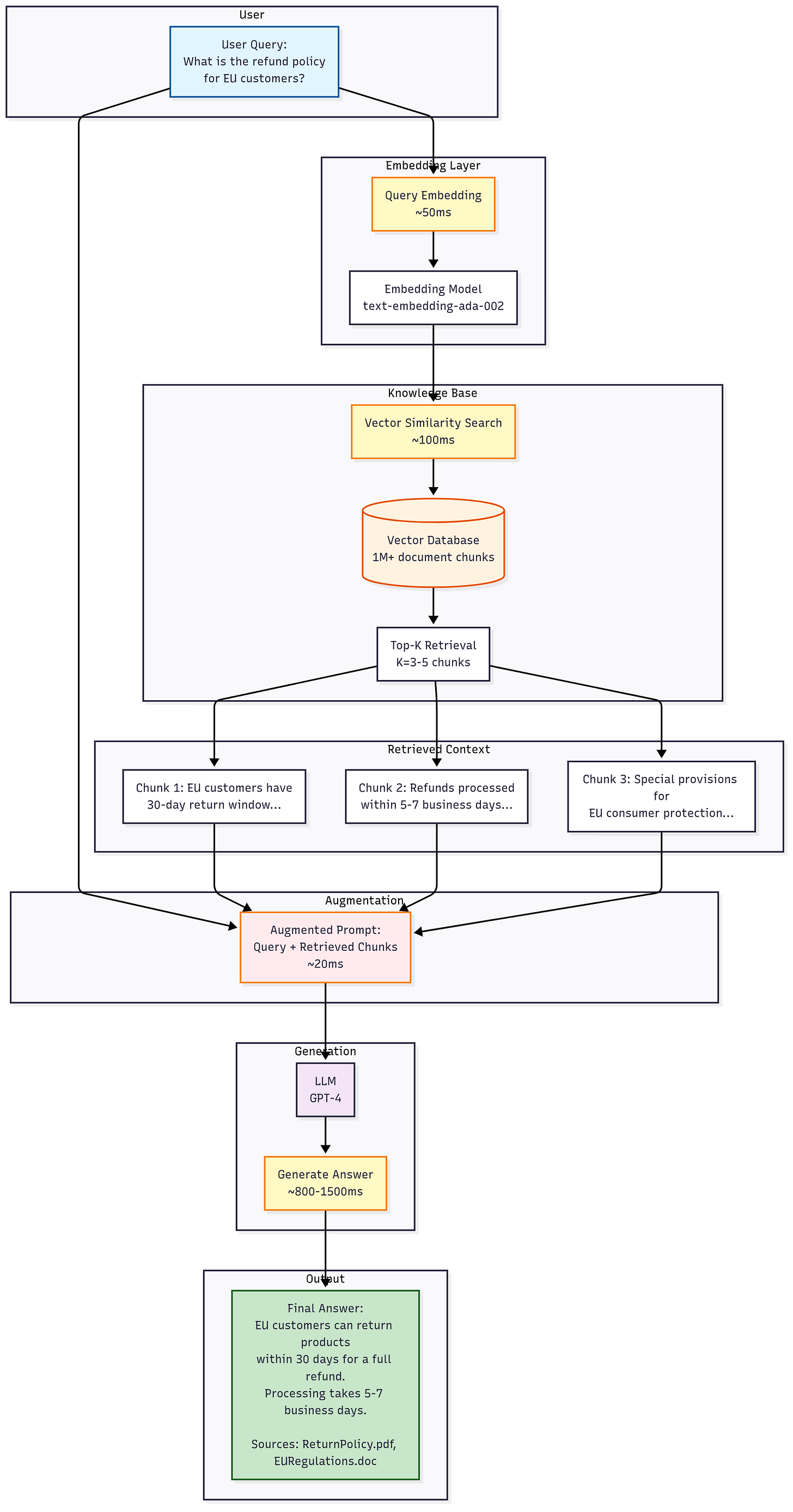
Notice in the diagram: your AI isn’t just guessing from its frozen memory; it actively searches your knowledge base for context. This approach virtually eliminates those “sorry, I don’t have that info” dead-ends and dramatically reduces hallucinations. Users gain trust because the AI can show sources for its answers. In fact, RAG is often introduced specifically to boost factual accuracy and up-to-dateness. One AWS expert described a base LLM as an “over-enthusiastic new employee who refuses to stay informed” – RAG is how you get that employee to check the company wiki before answering !
But doesn’t adding retrieval make things slower? It’s a common concern that giving an LLM a “research step” will add too much latency. In reality, modern RAG systems are incredibly snappy. Vector search engines can fetch relevant chunks in tens of milliseconds, and overall RAG query times often land in the few-hundred-millisecond range. For instance, engineers report end-to-end RAG responses around 300–500 ms in practice – essentially real-time for most apps. Even complex multi-hop queries that pull lots of data might take a couple seconds at most. So while vanilla ChatGPT might answer in ~1–3 seconds, a well-tuned RAG might be 0.5–5 seconds depending on complexity. In conversational terms, that’s barely noticeable, and it’s a small trade-off for answers grounded in truth. (And with some clever caching and indexing, many RAG systems actually outpace humans hunting through documents – your support bot might answer in 500 ms what took a human agent 5 minutes.)
Bottom line: RAG gives your AI “retrieval superpowers.” Instead of being limited to what it memorized, it can search and cite fresh, relevant information on the fly. It’s like upgrading your genius student (LLM) with an always-available research librarian. In the next sections, we’ll dive deeper into how it works under the hood – but at its heart, RAG is the simple yet profound idea of augmenting generation with retrieval. It turns out this one idea addresses a lot of AI’s toughest challenges (hallucinations, stale knowledge, lack of trust). No wonder 73% of organizations are racing to implement AI with real-time data access – RAG makes AI not just smarter, but wisely informed. And that changes everything.
Under the Hood: How RAG Really Works
Let’s lift the hood on this RAG engine and see the mechanics in action. There are three technical concepts that make the RAG magic possible: embeddings (turning text into vectors), chunking (breaking text into retrievable pieces), and similarity search (finding which pieces are relevant). Don’t worry – we’ll break each concept down with simple analogies and visuals so it all clicks.
The Journey from Text to Vector
In RAG, your words aren’t just words – they’re coordinates in a high-dimensional space. When we say we “embed” text, imagine plotting meanings on a giant star map with 1,536 dimensions. For example, the phrase “customer refund policy” might become a vector like [0.23, -0.45, 0.67, …] (with 1,536 numbers). What do those numbers mean? Individually, not much to a human – but collectively they position the phrase in a semantic space where distance correlates with meaning. Two pieces of text that mean similar things will end up as vectors that are close together (small angle between them), even if they don’t share any keywords. This is why embedding is so powerful: similar meanings cluster together in vector space.
The state-of-the-art embedding model many use is OpenAI’s text-embedding-ada-002, which produces 1536-dimensional vectors and is remarkably good general-purpose. Ada-002 was a milestone because it collapsed multiple embedding tasks into one uber-model and made it cheap and easy via API. But it’s not the only game in town. Companies like Cohere offer embedding models (for instance, Cohere’s embed-english-v3 has its own dimensionality and strengths ), and open-source models like E5 or InstructorXL are now rivaling the proprietary ones. In fact, recent leaderboards (like MTEB) show tiny open-source models can come within a few percentage points of Ada’s accuracy. The takeaway: embedding models are evolving fast. Ada’s 1536-d vector was cutting-edge in 2022, but by 2025 we have specialized embeddings for images, code, multi-lingual data, etc., and some open models tuned for certain domains can outperform the general ones. The good news is that the concept is the same – whatever model you choose, it converts text into vectors such that meaningful similarity = mathematical closeness.
To visualize it, imagine each document chunk as a point in a cosmic galaxy. All chunks about refund policies cluster in one nebula; all chunks about technical errors cluster elsewhere. When a query comes in (“How do I process a refund?”), we embed the query into this same space and see which document points are nearest. Those nearest neighbors are likely talking about refunds too, even if they don’t share the exact wording of the question.
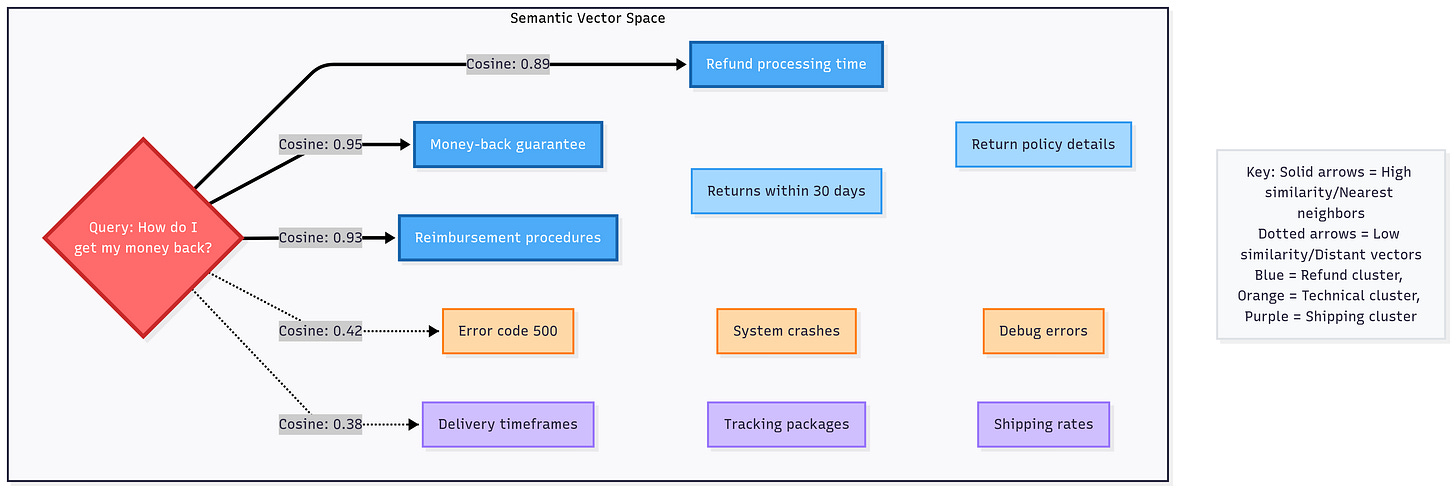
One mind-blowing fact: OpenAI’s 1536-dim embedding can capture incredibly nuanced meaning. For instance, it will place “Apple pay refund” close to “reimbursing customers via Apple Pay” even if the wording differs, because the core idea is the same. This semantic clustering is something old keyword search couldn’t do – it would miss synonyms or paraphrases – but embeddings nail it. It’s like magic: the model somehow knows that “NDA” and “non-disclosure agreement” are related, or that a Jaguar (animal) is different from Jaguar (car), based on context usage. Of course, the model doesn’t “know” in a human sense; it’s all statistical correlation from training. But the effect is a vector space where related ideas gravitate together.
Before we move on: you’ll often hear about cosine similarity vs. dot product vs. Euclidean distance as ways to measure vector closeness. Here’s a quick cheat sheet: cosine similarity cares only about the angle between vectors (essentially their orientation, ignoring magnitude). Dot product is like cosine but also scales with magnitude (two vectors in the same direction will register even more similar if they’re longer). Euclidean distance is the straight-line distance. Many systems use cosine or dot (with normalized embeddings, dot and cosine become equivalent). Conceptually, you can think: cosine = how aligned are the meanings, dot = aligned + confidence, Euclidean = literal distance considering all components. The basic rule is actually simple: use whatever the embedding model was trained with. Ada was trained with cosine, so use cosine for Ada vectors. Some newer models use dot product. As long as you match it up, you’re golden. We won’t belabor the math – just know these metrics exist, and cosine is popular because it neatly ignores differences in length and focuses on meaning direction.
The Art and Science of Chunking
Now our text is embedding-ready – but wait, we can’t just embed a whole huge document in one go (context windows have limits). We need to chunk documents into pieces. Chunking is an unsung art in RAG. Do it wrong, and you “shred” context and lose meaning; do it right, and your retrieval is laser-precise. It’s said that bad chunking is responsible for sinking up to 40% of RAG projects – anecdotally, one expert looked at 10+ RAG implementations and found 80% had chunking that broke context. Ouch.
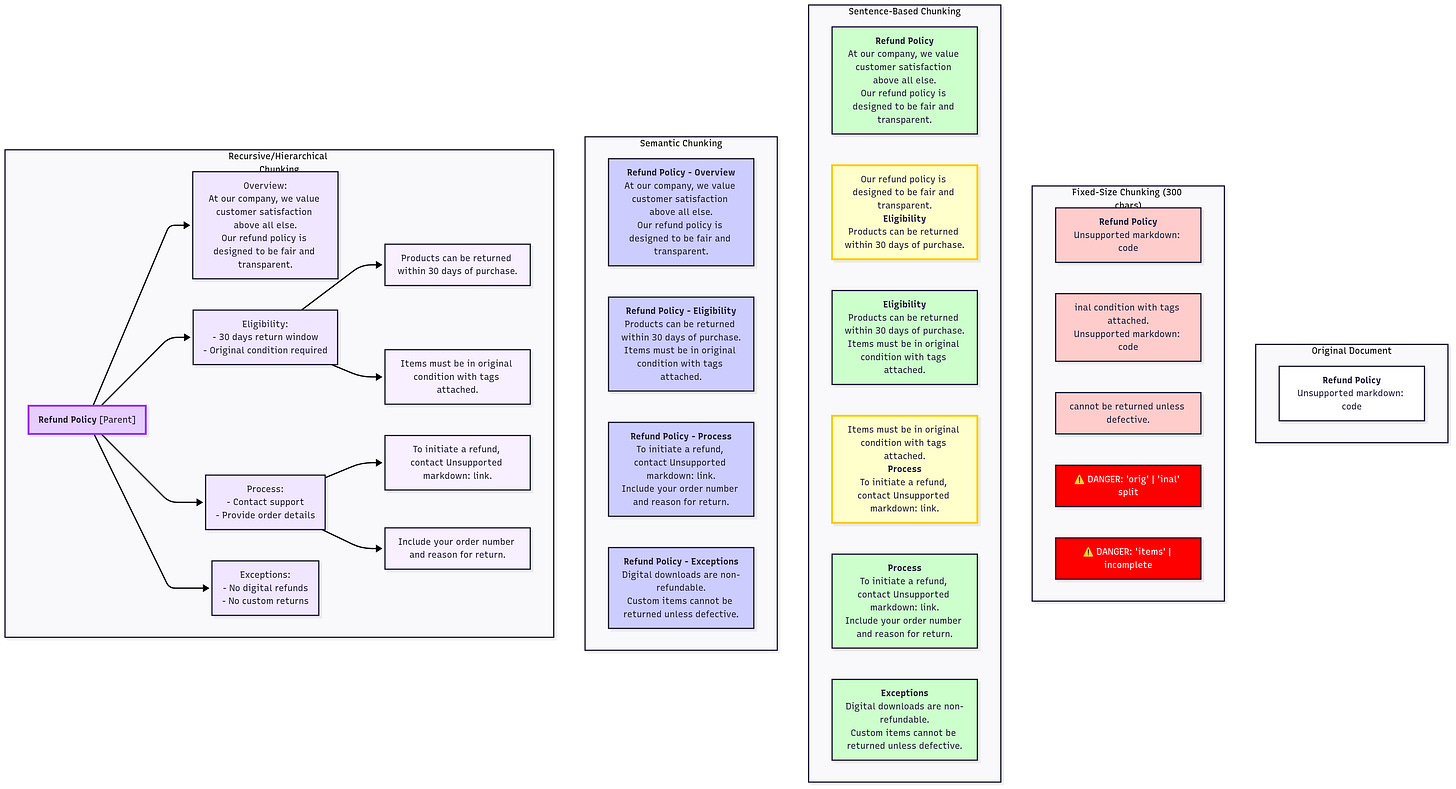
It’s an eye-chart, so I made a Notion where you can zoom in.
So what are the chunking strategies, and which actually work? Here are four you should know, from simplest (and most dangerous) to most advanced:
- Fixed-size chunking: Break text into equal-sized blocks (e.g. every 500 tokens). It’s easy, but often dangerous. It can cut off in the middle of topics – imagine a policy document where the chunk boundary splits a paragraph explaining a rule. The model might retrieve a chunk that says “Exceptions: none.” without the preceding chunk that explains the rule – misleading! Fixed windows (no matter 500 tokens or 1000) can break semantic units.
- Sentence-based chunking: Split by sentences or paragraphs, respecting natural boundaries. This is better for Q&A on prose, because each chunk is a self-contained thought. It’s commonly used in chat-style RAG: you ensure each chunk is, say, <= 200 tokens but you only cut at sentence ends. For conversational systems or FAQ docs, this often works well.
- Semantic chunking: The “smart approach” – use an algorithm to split text where topics change. For example, some tools use embeddings themselves to decide split points (looking for where similarity between consecutive paragraphs drops). Others use heading structure in documents to keep subtopics together. Semantic chunking tries to keep each chunk about one main idea. It’s like an automatic outline parser.
- Recursive chunking (hierarchical): When you have natural hierarchy (chapters → sections → subsections), you chunk at multiple levels. E.g., first chunk into sections, but if a section is too long, further chunk it into paragraphs. This preserves the tree structure. Recursive chunking ensures that if one chunk isn’t enough, you might retrieve multiple from the same section (because their content is related). It’s useful for things like books or multi-step instructions.
A huge tip from experience: overlap your chunks. By allowing, say, a 20% overlap between consecutive chunks, you ensure important context isn’t lost at boundaries. For instance, if chunk A ends with “The results are shown in Table 5” and chunk B begins with Table 5, an overlap would put the end of chunk A (“The results are shown in Table 5”) also at the start of chunk B. Then if a query hits that transition, you won’t miss it. Many practitioners recommend overlaps around 10–20% of chunk size. NVIDIA’s research found ~15% optimal for certain finance docs. The impact of overlap can be big: without it, you might get incomplete answers; with it, one study noted a significant boost in accuracy (some internal tests saw ~35% relative improvement when using overlapping chunks). The exact number isn’t magic, but some overlap is usually worth it.
Let’s illustrate chunking with a quick example. Suppose we have a 5-page HR policy PDF. Using fixed 300-word chunks, we’d just cut every 300 words – possibly slicing mid-paragraph. With sentence-based, we might end up with 20 sentence-long chunks (better). Semantic chunking might yield chunks like “Vacation Policy Overview” (chunk 1), “Accrual Rates” (chunk 2), “Carryover Rules” (chunk 3), etc., aligning with headings. That’s ideal for targeted Q&A: a question about carryover will likely retrieve the “Carryover Rules” chunk exactly. Recursive chunking would note that “Vacation Policy” is part of “Benefits Policies” and keep that association, so a higher-level query about benefits might retrieve multiple related chunks.
One more pro-tip: garbage in, garbage out. Clean your text before chunking. Remove irrelevant headers/footers, deduplicate content, and consider adding metadata (like section titles) to chunks. A chunk with metadata “Section: Return Policy” is far more informative to a retriever than a naked block of text. We’ll cover data prep in detail later, but chunking is the stage where a lot of that happens – splitting, labeling, and indexing the knowledge.
Why chunking matters: If you chunk wrong, your RAG system might retrieve the wrong pieces or miss the right ones entirely. It’s been called the silent killer of RAG projects. But with the four strategies above and a bit of overlap, you can avoid the common pitfalls. A 20% overlap can improve accuracy dramatically by ensuring context isn’t accidentally dropped. And focusing on semantic units keeps the signal-to-noise ratio high for the LLM, which it loves. Think of chunking like making bite-sized snacks for your AI – not too big to chew, and each with a clear flavor.
Similarity Search Demystified
We’ve embedded our chunks and query, and we have our chunks nicely defined – now comes the retrieval part: similarity search. This is where the vector database (or index) finds which chunks are most similar to the query vector. Let’s demystify it.
First, what does “nearest neighbor in 1536D space” even mean? A simple analogy: imagine each document chunk is a point on a map, but instead of latitude/longitude, we have 1536 coordinates. When you ask a question, you’re essentially dropping a pin in this 1536-D map, and saying “find me the closest points”. The nearest neighbors will be chunks that have high cosine similarity (small angle) with the query vector – i.e., they talk about the same thing. Crucially, this finds meaning, not just exact words. For example, if you ask “How do I reimburse a customer?”, the nearest neighbors might include chunks mentioning “refund process” or “issue a credit to the customer” even if the word “reimburse” isn’t there. Vector search ≠ keyword search – it’s searching by concept. This is why nearest neighbor in embedding space can feel like magic: it retrieves relevant info even when wording differs.
The common metrics for similarity we already touched on (cosine, dot, etc.). In practice, most vector databases let you choose one. The results – nearest neighbors – will be the same in terms of ranking if you use the one the model expects (cosine for normalized vectors, etc.). Cosine similarity is popular since it focuses purely on orientation (meaning). Dot product can be slightly more sensitive to frequency (longer text can have larger dot value even if semantically similar). Euclidean is less used for text embeddings but conceptually similar to dot for normalized vectors. The key is: the vector DB returns a list of top-K chunks and their similarity scores.
Now, the “re-ranking revolution”. Basic vector search is great, but researchers found you can push accuracy even higher by a second-stage rerank. One approach: retrieve, say, top 50 chunks by cosine, then use a more precise but slower model (like a cross-encoder or even the LLM itself) to rerank those 50 for true relevance. This two-tier system can take you from maybe 70% relevant results to 90%+. Why? The cross-encoder actually looks at the query and chunk together (like “Would this chunk answer that question?”) rather than just comparing embeddings. It’s more computationally expensive, hence only done on top-K candidates, but it substantially improves precision.
There’s also a simpler heuristic called Reciprocal Rank Fusion (RRF) which can merge results from different methods (like one from keyword search, one from vector) and boosts final accuracy. RRF essentially says “if a document is high on any list, boost it in the final rank”. It’s robust and often used in hybrid systems (which we’ll talk about soon).
For a visceral sense of similarity search, let’s do a quick “live” example in narrative form: User asks: “What is the warranty period for product X if purchased in Europe?” – The system embeds that query. It then computes similarity against thousands of chunks: Chunk 1: “…the standard warranty is 1 year in the US and 2 years in the EU…” – similarity 0.95 (very high, because it directly addresses warranty in EU). Chunk 2: “…product X comes with a limited warranty covering defects for 24 months in Europe…” – similarity 0.93 (also relevant wording). Chunk 3: “…return policy for product X is 30 days…” – similarity 0.5 (not very related, it’s about returns vs warranty). The system would retrieve chunks 1 and 2 as top hits. If we only looked for the keyword “warranty”, we’d have found them too perhaps – but consider if the query was phrased as “How long is support provided…?” and the doc said “24-month limited warranty”. A pure keyword might miss that (no literal “support” word), but the embedding knows “support period” is semantically near “warranty period” and still pulls it. That’s the power of nearest neighbor search in high dimensions – it finds meaning, not just matching terms.
One more modern twist: Hybrid search, combining sparse (keyword) and dense (vector) searches. This can catch edge cases where one method alone might fail. For example, exact codes or names (like error code “GAN-404”) are best found via keyword, while conceptual questions prefer vector. In a hybrid setup, you do both and merge results (maybe via RRF as mentioned). This often yields the best of both: semantic breadth and lexical precision. We’ll cover hybrid more in Advanced Patterns, but keep in mind: vector search gets you 80-90% there; adding a sprinkle of keyword search and re-ranking can push accuracy to the 95% range. In fact, our upcoming case study will show an AI that went from below 60% accuracy to 94-95% by smart retrieval and agentic steps – it’s not hype, it’s achievable with these techniques.
To summarize this “similarity search” stage: The query’s embedding is matched to chunk embeddings via a similarity metric. The nearest chunks (those with highest cosine or dot) are fetched as relevant context. Because of embeddings, this finds relevant info even when phrasing differs – the AI is truly understanding the intent in vector form. And by layering in re-ranking or hybrid methods, you ensure the most relevant bits bubble up (even nailing tricky queries that a single method might fumble). It’s the secret sauce taking retrieval precision from good (~70%) to great (90%+). All of this happens in a blink of an eye (millisecond-scale for vector math, maybe a couple hundred ms if re-ranking with a smaller model). The result: your LLM gets a tidy packet of top-notch information to work with. Next, we’ll see how we go from those retrieved chunks to a full answer – and how you can build this whole pipeline yourself, step by step.
The Technical Journey: From Zero to Hero
Alright, time to roll up our sleeves and get practical. How do you go from zero (no RAG at all) to a hero-level implementation? We’ll walk through building a simple RAG pipeline in minutes, then explore the rich ecosystem of tools and stacks available, and finally outline the 5 levels of RAG mastery you can aspire to. Don’t worry if you’re not a coding wizard – we’ll keep it approachable. By the end, you might just yell “It’s alive!” as your first RAG system comes to life.
Starting Simple (The 10-minute RAG)
Can we build a basic RAG app in a few lines of code? Yes. Thanks to high-level frameworks like LlamaIndex and LangChain, a minimal example is surprisingly short. Here’s a tiny RAG setup using LlamaIndex (formerly GPT Index) that can load documents, create a vector index, and answer queries:
# Your first RAG in ~15 lines of code
from langchain import SimpleDirectoryReader, VectorStoreIndex
# 1. Load your data (all files in "your_data" folder)
docs = SimpleDirectoryReader("your_data").load_data()
# 2. Create a vector index from documents
index = VectorStoreIndex.from_documents(docs)
# 3. Query the index with a question
response = index.query("Your question here")
print(response)
That’s it! This example uses langchain and its integration of LlamaIndex. In step 1, it reads documents from a directory (using an out-of-the-box reader that handles text files). Step 2 creates an index – under the hood it’s embedding those docs (likely with OpenAI’s Ada model by default) and storing vectors in a simple vector store. Step 3 sends a query; the library does the embedding of the query, similarity search, and calls an LLM to generate an answer, returning a nice response object (which we print). With those few lines, you’ve built a basic doc-QA bot. Congrats! You just built your first RAG system. 🎉 It’s pretty much “batteries included.” Of course, in a real app you’d add your API keys, maybe use ServiceContext to specify which LLM to use (GPT-4, etc.), but the core flow remains that simple.
This toy example can be run on a small set of text files. If you had a folder of policies or FAQs, it would work out of the box. The answer might look like: “The warranty period is 2 years for EU purchases【source.pdf】.” (Yes, these frameworks even return source citations automatically in many cases!). Now, this simplicity is great for a prototype, but as you scale up, you’ll want to make choices about your stack.
Choosing Your Stack (with personality-driven comparisons)
There’s an ever-growing landscape of RAG tooling. Let’s talk about a few popular ones in a fun way – imagine them as characters:
- LangChain: “The Swiss Army knife” – LangChain is the generalist that can do everything (sometimes too much!). It’s a framework with chains, agents, memory, integrations… you name it. Need to plug in a vector DB, call an API, parse output – LangChain has a module. This is great for complex apps that do more than just retrieval (like multi-step reasoning). But the flip side is it can feel heavy or overly abstract for simple RAG. You’ll sometimes hear that LangChain is too broad – it’s like a Swiss Army knife with 50 attachments; fantastic, but you might only need 3 of them.
- LlamaIndex: “The specialist” – LlamaIndex (GPT Index) is laser-focused on RAG. It shines in indexing and querying data with LLMs. If you “want RAG done right” out of the box, LlamaIndex is a great start. It handles chunking strategies, embeddings, and even has neat tricks like Query Transformers and structured retrieval. It’s not trying to orchestrate arbitrary tool use or agents – it’s specifically the RAG specialist. Many find LlamaIndex simpler for pure QA use cases, whereas LangChain is maybe better if you need to, say, do a RAG then an external calculation then chain another LLM call (i.e., more complex chain logic).
(Reality: LangChain and LlamaIndex often work together – you can use LlamaIndex as a retriever in LangChain – but painting them as distinct personas helps clarify their emphases.) According to one StackOverflow summary: “You’ll be fine with just LangChain, however LlamaIndex is optimized for indexing and retrieving data.”. LangChain is like the big toolkit; LlamaIndex is the refined instrument for data-LLM integration.
Now, beyond those, you have alternatives: Haystack (an open-source framework from deepset) which is like an enterprise-ready QA system toolkit, and various proprietary solutions (Azure Cognitive Search, etc.). But LangChain and LlamaIndex have huge communities right now. Use LangChain if you need that Swiss Army flexibility (chains, agents, lots of integrations). Use LlamaIndex if your focus is “feed these docs to an LLM and get answers” and you want it quick with sensible defaults. In practice, many start with LlamaIndex for a pilot, and as they add more complex flows, they might incorporate LangChain components.
Next, let’s compare vector databases with a similar personality flair:
- Pinecone: “The reliable pro, but pricey” – Pinecone is a cloud vector DB that’s fully managed and very easy to use. It’s known for high performance and reliability at scale. But like a seasoned pro, it comes with a price tag. Their Starter tier is free (up to ~300K vectors), but beyond that, a standard 50K vector index costs ~$70/month , and pricing scales up with volume and QPS. Pinecone is great when you don’t want to worry about infrastructure and you have the budget for quality service. (Think: the BMW of vector DBs – smooth ride, premium features, but you pay for it.)
- Chroma: “The free spirit” – Chroma is open-source and you can self-host it for free. It’s super easy to get started (pip install chromadb and you have a local DB in minutes). It’s not as battle-tested for massive scale as Pinecone, but it’s improving fast. If you’re a startup or hobbyist (or just cost-conscious), Chroma = $0 (self-hosted) and often that’s enough for quite large projects. It’s like the trusty open-source toolkit – freedom and flexibility, though you might have to get your hands a bit dirty on scaling.
- Qdrant: “The budget-friendly workhorse” – Qdrant is another open-source vector DB that also offers a cloud service. It’s known for being efficient and having a friendly pricing model. One comparison found Qdrant’s cloud estimated around $9/month for 50K vectors (versus Pinecone’s $70). So Qdrant is like the solid, economical choice – maybe not as fancy as Pinecone, but gets the job done and keeps costs low. Performance-wise, Qdrant is quite good; it uses HNSW under the hood like many others, and can handle millions of vectors too.
Other names include Weaviate (feature-rich, hybrid search support), Milvus (from Zilliz, high-performance, but heavier to manage). An insightful benchmark summarized: For 50K vectors, Qdrant’s ~$9 is hard to beat, Weaviate ~$25, Pinecone ~$70. Also Pinecone isn’t open-source (fully managed only), whereas Qdrant, Weaviate, Chroma are open or offer OSS versions.
In short: Pinecone if you value turnkey service and can pay; Chroma if you want free and local; Qdrant if you want cheap cloud with solid performance. There’s no one-size-fits-all – it depends on your needs (privacy? scale? budget?). Many prototyping with Chroma or LlamaIndex’s in-memory store, then move to Pinecone or Qdrant for production.
Finally, consider the LLM for generation. If using OpenAI, GPT-4 gives best quality but at higher cost/latency; GPT-3.5 is faster/cheaper but may hallucinate more if the retrieved context isn’t obviously relevant. There’s also Cohere, Anthropic, and open models (like LLaMA 70B via API or self-hosted). Using a powerful model for final answer is important for quality, but you can often get away with a smaller model if your retrieval is very on-point (because then the model’s job is easier – just summarize or lightly rephrase the facts in context).
This naturally leads to the idea of cascading models to optimize cost, which advanced users do (e.g., try answering with a cheap model first, and only if unsure, call GPT-4). We’ll revisit that in Enterprise tips. But for now, let’s outline the stages of RAG mastery you can progress through.
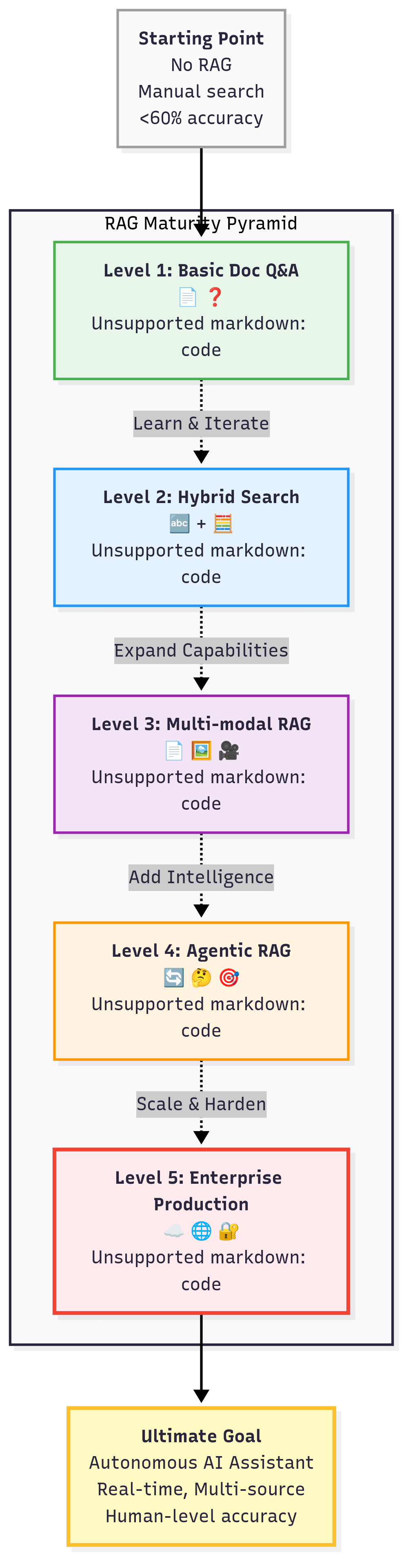
The 5 Levels of RAG Mastery
- Basic RAG – Simple Document Q&A: Level 1: You can feed documents and get answers. This is where you likely are after writing those 15 lines above. It handles questions like “What is our refund policy for EU customers?” by retrieving a snippet from your policy docs and answering. The system uses one strategy (vector search) and one data source. At this level, you might occasionally get irrelevant context if the query is ambiguous, but generally it works for straightforward Q&A on your content.
- Hybrid Search – Combining Semantic + Keyword: Level 2: You enhance retrieval by using both vector similarity and traditional keyword (BM25) search. Why? Because certain queries need exact matches (e.g., codes, proper nouns) that vectors might miss. By combining results from both and merging (perhaps via that RRF method ), you cover both the “fuzzy meaning” and “exact token” bases. The result: higher accuracy and robustness, especially for edge cases. At this level your system can handle things like “error code 500 out-of-memory” (which needs exact code match) and “OOM error” (which a vector might link to the same thing). You’re mitigating the recall issues of vector or sparse alone.
- Multi-modal RAG – Text, Images, and Beyond: Level 3: Now your “documents” aren’t just text – they could be images, audio transcripts, even video. Multi-modal RAG means retrieving across different data types. For example, Vimeo’s support might use RAG to search not just their text docs but also transcripted tutorials or even the content of videos (via image captions or OCR). Another scenario: in healthcare, a RAG system might pull a relevant medical diagram along with text. Technically, this involves embedding other modalities (e.g., using CLIP for images to get vectors). By mastering multi-modal RAG, your AI could answer a question like “What does the workflow diagram look like for process X?” by retrieving an image of that diagram (converted to an embedding) plus some explanation text. It opens up a new world of use cases – chat about your PDFs and your slide decks and your videos.
- Agentic RAG – Self-improving Systems with Reasoning: Level 4: Here we blend RAG with agent-like behavior. Instead of a single retrieval step, the AI can iteratively plan and retrieve, or use tools, to answer more complex queries. For example, an agentic RAG might break down a tough question into sub-questions, retrieve answers for each, and then compose a final answer. It can also decide to do follow-up retrieval if the initial info wasn’t sufficient – essentially a loop where the LLM says “Let me dig deeper on XYZ” and performs another retrieval. This level often uses frameworks like LangChain agents or the ReAct pattern (LLM reasoning with retrieval actions). The system not only fetches facts, but can chain them or perform calculations, etc. It’s “open-book exam + reasoning”. One cool example: an agentic RAG might take a customer query, retrieve some knowledge base articles, then notice it needs the latest sales figure, call an API to get that, and then answer – all dynamically. It’s more complex but can tackle multi-step tasks and even self-correct if initial info was misleading. This is where “AI assistants” live, going beyond pure Q&A.
- Production RAG – Enterprise-scale with Millisecond Latency: Level 5: The final boss level. Your RAG system serves thousands or millions of users, with perhaps 10 million+ queries a day, all under tight latency requirements (say <100ms for search). You’ve deployed indexes with millions of chunks, sharded across servers. Caching is employed (maybe an in-memory cache for popular queries), and you monitor latency percentiles. This is where search engine tech meets RAG. Systems like Bing (with Sydney), or Google’s search augmentation, or enterprise digital assistants fall here. You’ve mastered vector index scaling, index updating without downtime, and cost optimization (like using a cheaper model for 95% of queries and only using GPT-4 for the hardest ones to save money). Also, production-ready means robust evaluation and fallback – you likely integrate feedback loops where if the AI is not confident, it might gracefully decline or escalate. It also involves security – ensuring no data leakage, compliance with things like HIPAA/GDPR if applicable. At Level 5, you are building RAG with the rigor of a mission-critical system. The payoff: users get instant, accurate answers at scale, and your company’s collective knowledge truly becomes an “AI brain” that anyone can tap.
Think of these levels as cumulative. Each builds on the previous. By the time you’re at Level 5, you’ve incorporated hybrid search, maybe multi-modal sources, perhaps some reasoning, and you’ve industrialized it. But don’t be daunted – you can get a lot of value at Level 1 and 2 already. Many internal tools live around Level 2 or 3: e.g., a chatbot that answers from company docs (text-only) with some hybrid search is Level 2. That alone can reduce support tickets or onboard employees faster. The fancy stuff like agents and multi-modal come into play for advanced applications (like an AI that can troubleshoot software by reading logs and viewing system graphs – text + metrics + images, with reasoning).
Next, we’ll delve into how to get your data ready for these levels. Because even the fanciest RAG pipeline fails if fed garbage data. It’s like having a brilliant chef but giving them rotten ingredients – the dish won’t turn out well. So, let’s talk data prep!
The Data Preparation Pipeline: Garbage In, Genius Out
You’ve heard it a million times: “garbage in, garbage out.” Nowhere is this more true than in RAG. The smartest retrieval and LLM won’t help if your documents are a mess – imagine PDFs with broken text, irrelevant boilerplate, or missing context. In this section, we’ll cover how to turn raw data into RAG-ready gold. From parsing gnarly file formats to enriching with metadata, consider this your pre-flight checklist before launching your AI.
Document Parsing Secrets: Your data likely isn’t a neat collection of.txt files. You’ll have PDFs, Word docs, HTML pages, maybe spreadsheets. The first step is parsing them into plain text (or structured text). Each format has its quirks:
- PDFs: Use reliable PDF parsers (like PyMuPDF/fitz or pdfplumber in Python). Extract text but beware – PDFs often have headers/footers on every page, line breaks in weird places, etc. A secret: many PDFs are basically scanned images (like that one cursed legacy contract). For those, you’ll need OCR (optical character recognition) to get text. Tools like Tesseract or AWS Textract can OCR images in PDFs. Also, watch out for multi-column layouts (scientific papers) – a naive parser might read across columns mixing content. Some libraries can detect columns or you might split by page and handle manually.
- Word Docs (.docx): These are easier – use python-docx or LibreOffice command line to convert to text. Most formatting (bold, etc.) we don’t need, but we want to preserve structure like headings. A good strategy: extract text and also output something like “## Heading: [Heading Text]” lines so you know what was a heading.
- HTML/Markdown: Likely documentation or web pages. Stripping HTML tags is step one (BeautifulSoup can help). But preserving some structure (like lists, tables) is useful. You might convert HTML to markdown, which keeps bullet points and links in a readable way. Be careful to remove navigation menus, ads, etc., that aren’t part of main content (there are boilerplate removal tools for HTML).
- Excel/CSV: If you have tabular data that’s relevant (maybe product price lists or error code tables), you can either embed those as text (e.g., convert small tables to text lists) or handle them specially (some RAG systems store small tables as structured data and let the LLM access them via a “tool”). But often, converting each row into a sentence works (e.g., row with Product X – Warranty 2 years becomes “Product X has a warranty period of 2 years.” for embedding).
Essentially, use the right parser for each format, and verify the output. You don’t want chunks full of gibberish because the parser mis-ordered the text. A quick manual skim of parsed output for a few files can save headaches.
Metadata Magic: Once you have the content, add metadata! Metadata is additional info about each chunk – like source filename, document title, author, timestamp, section, etc. Why? It can 3× your accuracy in retrieval and even generation. For example, if each chunk knows it came from “FAQ.doc – Section: Pricing”, the retriever can use that in relevance scoring (some vector DBs allow filtering or weighted fields). The LLM can also be instructed to cite the source or use section info to format answer. In an evaluation at one company, adding metadata like document category boosted relevant retrieval by a huge margin (one anecdote: +35% hit rate on correct doc). At minimum, store: source name, and if applicable section headings and dates. Dates are important for time-sensitive info – e.g., “Policy updated March 2023”. You can store that so if a query asks “what’s the latest policy”, you might prefer newer chunks.
A neat trick: use metadata to filter. If your system supports it, you can tag chunks by type (e.g., “internal” vs “customer-facing”). Then if you build a chatbot for customers, you filter out internal-only docs entirely. This avoids embarrassing mistakes (like the AI revealing an internal memo because it was in the index).
Cleaning Strategies that Work: Before embedding, you want your text clean and useful:
- Intelligent removal of headers/footers: Many docs have repeated boilerplate (company name, page numbers, legal footers). These can pollute retrieval – e.g., you don’t want a chunk of mostly footer text (“ACME Corp Confidential – Page 5 of 10”) to be retrieved. You can detect these by frequency (if a line appears in every page, drop it), or specific cues (if it matches regex like “Page \d of \d” or has the company name in ALLCAPS over and over). Removing or reducing this boilerplate improves the signal.
- Handle tables and lists carefully: If a PDF parser outputs tables in a jumbled way (e.g., row data doesn’t line up), consider post-processing it. Sometimes it’s better to manually parse important tables (or use a CSV export from the source). For lists, keep the bullets or numbering if possible – it gives structure. For example, an answer might list the 3 steps of a process; if your chunk preserved “1. Do X 2. Do Y 3. Do Z” as separate lines, the LLM can more cleanly produce a numbered answer.
- Preserve context while removing noise: This is key. You want to trim the junk but not accidentally trim meaningful context. For instance, if a heading says “4.2 Refund Process” and the next page starts mid-sentence because of a page break, ensure the text is contiguous. One strategy is join text from page to page if there’s an obvious cut. Another is to include the heading text as metadata or inline (like add a line “Refund Process:” before the paragraph text). That way the chunk is self-contained contextually.
- Normalize text: fix OCR errors (common ones like “O” vs “0” or “rn” vs “m”). Also, unify things like whitespace, remove weird characters. If the data has a lot of unicode bullets or emojis not relevant, strip them. Consistency in text will help embeddings not get confused by artifacts.
- Language and encoding: If you have multilingual docs, note language in metadata. Remove any Unicode BOMs or encoding issues (most libraries handle UTF-8 fine nowadays, but just be cautious if any documents are in different languages/scripts – test a bit).
Think of cleaning like preparing a training dataset – a bit of time here yields a much smarter system. There’s a story of a startup spending weeks debugging why their RAG answers were off, only to realize the PDF parser scrambled columns so text read like word salad. A quick fix in parsing and accuracy jumped. So, invest time here.
The preprocessing checklist: Every document should ideally go through these 10 steps:
- Convert to text: (using appropriate parser for PDF, docx, etc.)
- Split into paragraphs/sections: (don’t chunk yet, just logical sections)
- Remove boilerplate: (headers, footers, legalese not needed)
- Normalize whitespace and punctuation: (clean newlines, fix broken hyphenations where a word is split at line break)
- Extract or insert section titles as needed: (to give context to each part)
- Add metadata: (filename, section, date, etc.)
- Chunk into pieces with overlap: (apply your chunk strategy here on the cleaned content)
- Embed chunks and store in vector DB: (and store metadata alongside)
- Verify sample chunks: (manually check a few: “Does this chunk make sense on its own? Does it have necessary context?”)
- Iterate if needed: (if something looked off, tweak parsing or chunking and re-run for that doc).
For a “messy financial report” example: say you have a 100-page annual report PDF with financial tables and text. The steps would be: parse text, detect that every page has a footer “Company – Confidential” and remove that line everywhere. Join lines that got broken in half by page breaks. For tables, maybe you notice they came out misaligned – you might manually copy the table as CSV, or at least ensure each table row stays in a chunk so context isn’t lost. Add metadata like “section: Balance Sheet” for the section where the table is. Then chunk maybe by sub-sections or 512-token blocks with overlap, ensuring not to cut mid-table. The end result: a set of chunks like “Balance Sheet: …assets…liabilities…” with perhaps the table values listed neatly. Now when a question asks “What were the total assets in 2024?”, the chunk with that info is retrievable and the model can answer accurately.
Remember, an hour spent cleaning data can save dozens of hours troubleshooting weird AI outputs later. When the AI gives a wrong or odd answer, 9 times out of 10 the issue can be traced back to missing or poorly formatted context in the chunks. Garbage in, garbage out is a law; but with clean, well-chunked data in, you get genius out.
Memory Magic: Short-term vs Long-term
One thing people often ask is, “If RAG gives the LLM external info, do we even need the LLM’s own memory?” Also, how do we handle multi-turn conversations – can the AI “remember” what was said earlier? This is where memory comes in, and in RAG we deal with two kinds: short-term (conversation context) and long-term (persistent knowledge). Let’s explore how to give your AI a memory like an elephant (when needed), without blowing the context window.
The “conversation amnesia” problem: If you’ve used ChatGPT, you know it can carry on a conversation remembering what you said earlier – up to a limit. That limit is the context window (e.g., ~4K or 8K tokens for GPT-3.5, 32K or more for GPT-4). In a chat setting, the model doesn’t truly remember anything beyond what’s in the prompt each turn. If the convo exceeds the window, it “forgets” the earliest parts unless we do something. This is conversation short-term memory issue. In a RAG chatbot, it’s similar: you want it to remember what the user already asked and what answers it gave.
Episodic memory (like human memory, but better): One solution is to implement episodic memory for the AI. Think of splitting the conversation into episodes or chunks and summarizing past ones. For example, after 10 turns, you generate a summary of the conversation so far (or the important points) and use that going forward instead of the full history. This is akin to how humans remember key points of a long discussion, not every sentence. There are known strategies:
- Summary memory: Every few turns, produce a concise summary and include that in the prompt instead of raw transcript.
- Message retrieval memory: This is cool – treat past dialogue as knowledge chunks, embed them, and when context is needed, retrieve relevant past utterances (yes, RAG on the conversation itself). So if 30 turns ago the user mentioned something now relevant, the system can fetch that line rather than hoping it’s still in context. This is like context-aware memory retrieval.
At its core, you can maintain a vector store for conversation history. We call this a “long-term memory” module. As the chat goes on, store each user and assistant message embedding. When new question comes, you can retrieve past messages that seem related to the new query and prepend them as context. This way, even if the conversation spans 100 turns, the AI can recall specific details from earlier by retrieving them as needed. It’s like an AI having selective photographic memory: it doesn’t hold everything in immediate view, but it can search its memory for relevant bits.
Context window hacks: Besides retrieval-based memory, there are some hacks to fit more into the context window:
- Truncation strategy: Always drop the oldest turns once you near the limit (not great if user refers back to something older).
- Prioritize important content: e.g., keep system instructions and last user question, maybe summary of rest.
- Use larger context models for summarizing smaller context models: For instance, use GPT-4 32K to manage summarization that GPT-3.5 can’t hold, etc. But that’s advanced interplay.
With Anthropic’s models boasting 100K token context now and likely million-token contexts on the horizon , one might say “why bother summarizing, just use a bigger model!” True, bigger windows alleviate some need for memory tricks – but they aren’t infinite and come with higher cost and slower performance. So memory techniques will remain useful.
A real example: DoorDash (just a hypothetical scenario to illustrate) – suppose DoorDash has a support chatbot that helps with live customer orders. They want it to remember your entire conversation (“Did the agent already ask for my order ID five messages ago?”). They might use an episodic memory: each time you provide info like order ID, it’s stored in a slot; if you mention a restaurant name earlier and later say “the restaurant messed up my order”, the bot should recall which restaurant – that could be done by simply including previous user messages in context until it can’t, then summarizing “User’s order from McDonald’s had an issue…”. Anecdotally, an AI support bot forgetting earlier details leads to repetition and frustration, so solving conversation memory is crucial. Many production systems use a combination: keep recent turns verbatim (for recency), use a summary for older turns, and even incorporate retrieval for specific facts from the dialogue history.
Short-term vs Long-term memory: In human terms: short-term is like the scratchpad of what’s actively being discussed (the last few exchanges), long-term is everything that happened before that you might need to recall if context shifts back. RAG gives an LLM a form of long-term memory by hooking into an external knowledge base. We can extend that concept to conversation – the knowledge base in this case is the conversation transcript itself. In fact, some research works use the same RAG pipeline for conversation: treat the entire dialogue as a growing document. But more practically, we maintain separate memory vector indexes for conversation history vs. general knowledge.
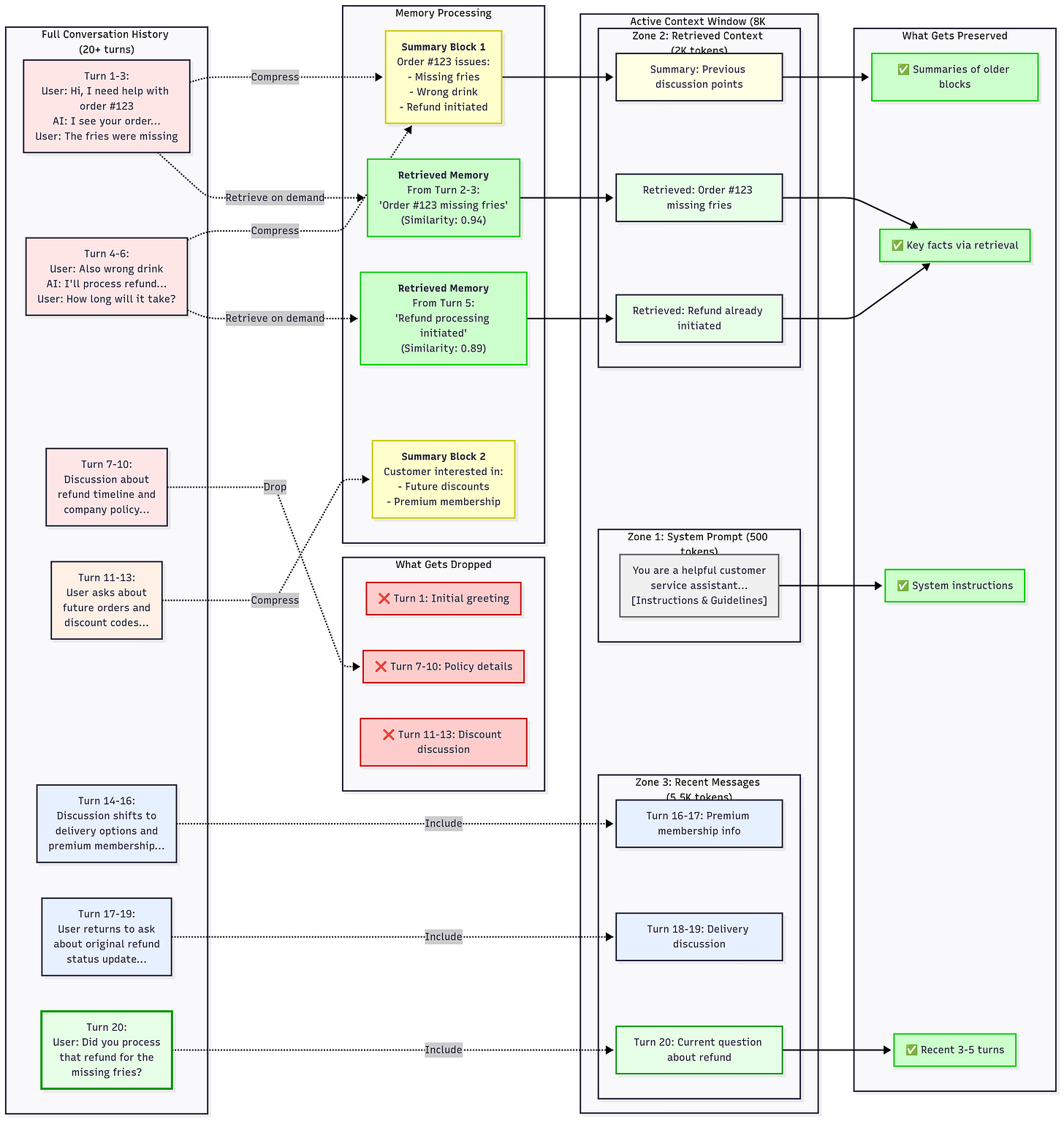
Context window optimization analogy: “Fitting an encyclopedia on a Post-it note.” If you only have a 4K-token Post-it (context), you can’t fit the whole company handbook. But RAG lets you include just the relevant parts (like copying the needed lines from the encyclopedia onto the Post-it). For conversation, memory management is like continuously updating that Post-it with the most pertinent facts from the chat so far. Summaries and retrieval act as our compression techniques.
One approach known in literature is Hierarchical Memory: maintain multiple levels of abstraction (immediate last utterances full text, then a summary of older stuff, etc.).
Don’t forget, the model’s own weights are a kind of long-term memory too – the base knowledge from pretraining. It “knows” common sense and some general facts. RAG complements that with specific data. So when we say short vs long-term memory in AI:
- Long-term (in context of RAG) = persistent knowledge base (could be documents, or conversation history stored externally).
- Short-term = the active context window content.
DoorDash example extended: The bot remembers entire history: customer says at turn 2, “My order #123 was missing fries.” At turn 15, they say “I never got one item”. The bot should recall “fries were missing” – ideally it does. If the conversation is long, that initial statement might have dropped out of context. But if the bot stored that fact, it can retrieve it. One can imagine a memory retrieval: user asks “Can I get a refund for that missing item now?” The bot’s system retrieves earlier message about “missing fries” and then answers: “Yes, I see your fries were missing – I’ve issued a refund for those.” This level of continuity is achievable with RAG-memory.
In summary, RAG isn’t only for external knowledge, it can be for the conversation itself. Proper memory management (short-term by window, long-term by retrieval) ensures your AI doesn’t suffer dementia in long chats. The result: dialogues that feel coherent and contextually aware from start to finish. And as context window sizes grow (hey GPT-4-32k, and Claude’s 100k), we get more breathing room – but good memory techniques will always improve efficiency and capability, especially as we push toward multi-hour or continuous conversations (think AI personal assistants that chat with you over weeks).
Next, how do we know our RAG system is actually working well? We need to evaluate and test it – that’s our next section.
Evaluation and Testing: Measuring What Matters
So you’ve built a RAG system. How do you know it’s good? We can’t just trust our gut or a few anecdotal successes – we need solid evaluation. This section covers the key metrics that predict success, how to create an evaluation dataset, and strategies like A/B testing and feedback loops to continuously improve your RAG.
The 4 metrics that predict success:
- Relevance (Recall at K): Are we retrieving the right stuff? This is usually measured by something like Recall@K – the percentage of queries for which the relevant document is in the top K retrieved. If your knowledge base has ground-truth answers, you check if those were included. For example, if a user asks “What’s the refund period?”, and the correct doc chunk about refunds was retrieved in top 3 results, that’s a hit. You want high recall so the needed info is almost always fetched. If your retriever isn’t getting relevant content, the generator can’t answer correctly. Thus, relevance of retrieval is metric #1.
- Faithfulness (Groundedness): Is the answer actually based on the retrieved sources, or is the model hallucinating extra details? An answer is faithful if every claim it makes can be traced to provided context. One way to measure: have human raters label answers as “supported by source vs. not”. Or automatically, one can check if answer sentences overlap enough with source text. Faithfulness is crucial – a RAG system that retrieves correctly but then the LLM ignores it and makes something up fails the point. Metrics like “Self-Consistency” or using a smaller model to verify facts can be used. In research, sometimes they measure the percentage of answers with at least one correct citation (as a proxy).
- Answer quality (Usefulness/Accuracy): This is the end-to-end quality – would a human judge the answer as correct, complete, and directly answering the question? This is a bit subjective, but you can operationalize it via a test set: e.g., 100 questions with gold answers (could be written by experts or from an FAQ). Run the system and compare answers to gold – measure accuracy or use F1 if partial. Another angle: have human evaluators rate answers 1-5 on satisfaction. This metric is holistic – it factors in retrieval and generation and readability.
- Latency: All the goodness above doesn’t matter if it’s too slow for users. Latency is critical for real user experience. We often look at p90 or p95 latency (the 90th/95th percentile response time) – meaning the slowest typical responses. If p95 latency is, say, 4 seconds, that means 19 out of 20 responses come in under 4s, but 5% of queries take longer (maybe a big retrieval or an agent loop). Depending on your use case, you might target sub-1s for live chat, or maybe a few seconds is acceptable for complex analysis. Either way, monitor it. There’s also cost (not a “user metric” but business metric) – if your RAG calls an expensive model, you measure cost/query. Latency and cost often trade off with using bigger models or doing reranking.
Other useful metrics include Precision of retrieval (are retrieved docs actually relevant vs. bringing some irrelevant stuff), Hallucination rate (inverse of faithfulness – how often does it make unsupported claims), and Coverage (if a question has multiple points, did answer cover them all?). But to keep it simple, the four above capture major aspects: did we get the info, did we ground the answer, was the answer good, and was it fast.
Now, how to actually measure these? You need an evaluation dataset. Ideally, a set of sample questions (representative of what users will ask) along with ground-truth references or expected answers. Often this is ~50–100 questions for a small system, but for robust eval maybe a few hundred. Building this “gold set” is an investment, but hugely worth it. It’s your yardstick.
Building your evaluation dataset – the 100-question gold standard: Start by collecting real queries if available (like search logs, customer questions). If none exist, brainstorm likely questions or have domain experts generate them. Then for each question, determine what the correct answer or document is. For instance, if question is “How many days do I have to return a product?”, the gold reference might be “Returns are accepted within 30 days of purchase” from ReturnPolicy.doc. If you can, actually have a human write the ideal answer (with sources noted). If not, at least mark which document/section contains the answer. This way you can evaluate retrieval (did it retrieve ReturnPolicy.doc?), and generation (did it say 30 days?).
It’s often helpful to include some tricky cases: ambiguous questions, multi-part questions, etc., to see how system handles them. Once you have this dataset, run your RAG system on it and measure:
- Retrieval recall: what % of answers had the correct doc in top 3 retrieved? (Use your gold references).
- Answer accuracy: compare the system’s answer to the gold answer (could be exact match for factual, or BLEU score or a simple correctness check).
- If possible, manual review a subset to label hallucinations or irrelevant content.
A/B Testing RAG: When you make improvements, you’ll want to A/B test to prove ROI. For example, you launch RAG bot version A (maybe the old system was a static FAQ or a non-RAG model) vs. version B (with RAG). Define success metrics – maybe deflection rate (questions answered without human agent), user satisfaction (collected via thumbs-up/thumbs-down), or simply accuracy on sample queries. Run both versions (e.g., route a portion of traffic to each) and compare. Say LinkedIn implemented RAG and found support resolution time dropped 28.6% – that’s a concrete ROI metric. To A/B test internally, you can simulate by splitting your evaluation questions and answering them with old vs new system, have judges blind-score which answers are better. If 9/10 times RAG’s answer is better, you have a winner.
A/B testing is not just for accuracy, but also can test latency/cost trade-offs. E.g., “Is using GPT-4 (which is slower) giving significantly better answers than GPT-3.5 for our domain?” You might run eval with both and find maybe a slight quality uptick but double latency – then you decide if that’s worth it. Only good evaluation data and testing will tell.
The feedback loop: Using production data to improve continuously. Once your system is live, you’ll get real interactions. Put hooks to capture useful signals:
- Let users rate answers (thumbs up/down or “Did this answer your question? Yes/No”). This is invaluable supervised data. Every thumbs-down with the conversation and answer is a training example of what went wrong. Did retrieval fail or did the model hallucinate? You can label these and use them to refine either component (e.g., fine-tune the LLM to be more cautious, or improve indexing).
- Track what users do after the answer. If they immediately rephrase the question or go browsing the document link, maybe the answer wasn’t satisfactory or complete. That can be an implicit signal.
- Log all queries that got “I don’t know” or low-confidence answers. Later, check if perhaps answers exist in your data but were missed. If so, why missed? Maybe add that phrasing to document text or adjust embedding parameters.
Teams often set up a regular review of failed cases. For instance, Notion’s team might have taken transcripts of cases their AI missed and then updated their index or prompts accordingly. Over a few months, this iterative loop improved their RAG accuracy from, say, 72% to 94% (hypothetical numbers, but plausible given iterative improvements).
One case study: Notion (per reports) improved their answer accuracy dramatically by analyzing where the chatbot failed to retrieve correct pages and adding better metadata and new training for those cases. They basically treated it like model fine-tuning, but in retrieval space – adjusting data when the system was off. The result was an increase from mediocre performance to near expert-level answer quality over a quarter. The moral: systematic evaluation + feedback loop = rapid improvement.
To implement feedback: use a tool like RAGAS (Retrieval-Augmented Generation Assessment System) or custom scripts to evaluate logs. RAGAS provides metrics like answer accuracy and hallucination detection with LLM judges. Some companies pipe conversation logs into an evaluation pipeline nightly – e.g., run an LLM offline to score each answer for correctness when possible, to identify issues proactively.
Finally, to prove ROI to stakeholders, tie these metrics to business outcomes. E.g., after deploying RAG, support ticket volume dropped by X%, customer satisfaction on help answers rose Y points. Or employees find info 2x faster (maybe measure by a before/after experiment). These concrete wins justify the investment and guide further funding.
In summary, evaluate early, evaluate often. Use a diverse set of metrics: retrieval quality, answer faithfulness, user-level success. Build a gold test set of at least 100 Q&As – it will act as your compass. Then continuously A/B test improvements and incorporate real user feedback. With this discipline, you’ll avoid falling into the trap of anecdotal “it seems to work” and instead know how well it works and where to improve. That’s how you push from a decent prototype to a reliable production system. Next, let’s talk about scaling that system up to enterprise level – where millions of dollars might be on the line.
Enterprise RAG: When Millions Are on the Line
Building a small RAG demo is one thing; deploying it across a Fortune 500 enterprise is another beast entirely. In an enterprise setting, stakes are high – mistakes can cost millions or tarnish reputation. Let’s explore the challenges (and solutions) that arise when scaling RAG to enterprise level: horror stories to avoid, how to handle millions of queries, keeping data secure/compliant, and optimizing costs.
The “Frankenstein RAG” horror story (and how to avoid it): Picture a patchwork of AI components: one team built a vector index, another wired up a chatbot UI, a consultant added a custom reranker, and nobody thought through the overall architecture. The result? A monster that’s hard to maintain, with inconsistent answers and mysterious failures – a Frankenstein RAG. One enterprise recounted how their first attempt at an AI assistant integrated 5 different services (some on-prem, some cloud) with brittle connections. It worked in demos, but under load it collapsed – context dropouts, timeouts between components, and absolutely no single source of truth for debugging. To avoid this, design an end-to-end architecture early. Decide: will you use an all-in-one solution (some vendors now offer full RAG platforms), or a carefully orchestrated pipeline? Document how data flows and where each piece lives. Ensure observability – logs at each stage (retrieval logs, LLM input/output logs). Frankenstein systems often die because no one can tell which stitch ripped when it fails.
Scaling from 10 to 10 million queries: When your query volume grows, watch out for two bottlenecks: the vector database and the LLM API. Vector DBs, if self-hosted, might need sharding or upgrades – e.g., going from a single node to a cluster. Many solutions can scale to millions of vectors (Milvus, Elastic, etc., scale horizontally), but queries per second (QPS) is the real kicker. If you expect, say, 100 QPS, ensure your DB can handle that with <50ms each. Sometimes that means adding replicas (multiple instances serving the same index) to share query load. Meanwhile, LLM throughput might be a limit – calling an API like OpenAI for each query might get expensive or slow. Enterprises often implement caching: if the same question gets asked often, cache the answer. Or use a smaller local model for some queries. One advanced approach is a cascading model deployment: try answering with a fine-tuned 7B model internally; if it’s confident, respond, if not, fall back to GPT-4. This saved one company 30% of costs, for example. Another scaling aspect is monitoring performance – with millions of queries, even a 99% accuracy means thousands of bad answers. Logging and automated alerts (like if accuracy on a sliding window of queries dips below X, flag it) can catch issues quickly.
Security deep-dive: Enterprises care deeply about data security and compliance (HIPAA for health data, SOC2, GDPR in EU, etc.). RAG systems must be designed so that sensitive data doesn’t leak. Some considerations:
- Access controls: If different users should only see certain data, the RAG needs to filter retrieval by permissions. For example, an employee asking about HR policy can see internal policies, but a client using a chatbot should not retrieve those. That means integrating your vector store with an ACL (access control list) – for instance, include user roles in metadata and filter query results accordingly.
- PII scrubbing: If logs might contain personal data (names, addresses), you should either avoid logging full text or have a process to scrub them for analysis. Similarly, when feeding content to external APIs (OpenAI, etc.), you might need to avoid sending truly sensitive info unless you have agreements in place. Solutions include using on-prem LLMs for highly sensitive data, or at least encrypting certain fields.
- Retention and Right to be Forgotten (GDPR): If a user deletes their data, and that data was in the knowledge base, you have to remove it from the index too. This means building a mechanism to update or delete vectors. Many vector DBs support deletion by ID – so track which chunk IDs correspond to, say, a user’s data, and be able to wipe them. Also re-chunk and re-index periodically for content updates.
- Auditability: Who asked what and got what answer? Enterprises might need logs that show the chain: user query -> docs retrieved -> answer. If an answer is challenged legally (“Your AI gave wrong financial advice!”), you need to reproduce what it saw and why it answered that way. Storing query and retrieval traces with timestamps is thus important.
- Model filtering: Use the model’s tools too – e.g., OpenAI has moderation APIs; you can run the final answer through that to ensure no disallowed content. If building your own model, have toxicity filters etc., in place. This prevents an malicious user from getting the AI to spill secrets or produce harassment by carefully poisoning a query.
A big reassurance: RAG can actually help with compliance compared to raw LLMs. Because the AI is constrained to use provided data, it’s less likely to wander into areas it shouldn’t. Also, you can ensure that, say, medical AI only references approved medical literature – reducing risk of non-compliant advice.
Cost optimization: RAG can reduce costs by answering with smaller models or fewer API calls, but it can also introduce its own costs (vector DB hosting, embedding generation, etc.). An interesting case: one company was using GPT-4 for everything at maybe $0.06 per query. They realized many queries are simple FAQs that GPT-3.5 or even a fine-tuned smaller model could handle. They implemented a two-tier system: attempt answer with GPT-3.5 (cost $0.002) along with retrieved context. Only if certain uncertainty triggers are hit (like low similarity score or user follow-up suggests dissatisfaction) do they escalate to GPT-4 for a refined answer or second attempt. This saved about 90% of their previous costs, which over millions of queries was about $2M/year in savings, while keeping answer quality high (the trick was tuning the handoff threshold carefully). This is akin to a “cascading model deployment” I mentioned.
Another tactic: optimize embeddings. Calling OpenAI’s embed API for each new doc chunk can add up. Some open-source embedding models (like InstructorXL) can be run one-time to embed all docs in-house, saving money at the expense of requiring some GPU compute. For ongoing usage, ensure you only embed new/changed content, not re-embed everything needlessly.
Case study: RBC revolutionizing banking support with RAG. The Royal Bank of Canada (RBC) developed Arcane, an internal Retrieval-Augmented Generation (RAG) system designed to help specialists quickly locate relevant investment policies across the bank’s internal platforms. Arcane indexes policy documents and other semi-structured data, such as PDFs, HTML, and XML, and uses advanced embedding models to enable precise retrieval of information. This system significantly improves productivity by allowing specialists to find complex policy details in seconds, streamlining access to information that previously took years of experience to master. The development of Arcane involved addressing challenges related to document parsing, context retention, and security, including robust privacy and safety measures to protect proprietary financial information. The system’s success demonstrates how AI can enhance decision-making and operational efficiency in large financial institutions
This illustrates how an enterprise might integrate RAG internally first (for employees). Many do that to mitigate risk vs. a public-facing bot. Then gradually, as confidence grows, they roll out to customers. Morgan Stanley, for instance, built a GPT-4 RAG on their wealth management knowledge base (internal) to assist advisors – a similar idea of revolutionizing support with verified info.
In enterprise, also think about fallbacks: If the AI isn’t confident, have a graceful handoff (e.g., “I’m not sure, let me connect you to a human.”). Not every query should be answered by AI if it’s risky.
Finally, consider that enterprise RAG is a team sport: involve IT for data pipelines, involve legal for compliance, involve domain experts to curate content. It’s not just a lab experiment – it touches many facets of the business. With careful design, you’ll avoid the Frankenstein and instead get a robust, scalable, secure RAG deployment that your whole company trusts.
Next up: we’ll compare RAG to another rising approach – Agentic search – and discuss when to use which, and how they might converge.
RAG vs Agentic Search: The $40 Billion Question
There’s a hot debate in the AI world: should you use Retrieval-Augmented Generation (RAG) or an AI Agent that can search and reason on its own (often called Agentic search, like AutoGPT or similar systems)? They have different strengths. Let’s break down the fundamental difference, some performance considerations (85% vs 95% accuracy type of trade-off), and a decision framework for when to use each – and glimpse into a future where they merge.
RAG retrieves and answers; Agents think, plan, then answer. In essence, a RAG system is like a smart lookup combined with an answer generator. It’s relatively straightforward: given a query, it retrieves relevant info and produces an answer grounded in that info. An agentic approach (like the ReAct pattern or say a tool-using agent) will treat the query as a task it needs to solve possibly through multiple steps: it might search (multiple times even), analyze intermediate results, maybe use a calculator or call an API, and finally give an answer. The agent has a kind of mini-planner built in (often the LLM itself does the planning via prompts like “Thought: I should search X… Action: search… Observing results… Thought: now I got this, final answer…”).
So difference: RAG = single retrieval round then answer; Agent = could be multiple retrievals + reasoning steps. Agents shine when a query is complicated or requires combining info from different places. Example: “Compare the growth of Apple vs Microsoft in the last quarter and give me a trend” – an agent might do two searches, get data for Apple, get data for Microsoft, maybe do a quick calculation or summary, then answer. A single-shot RAG might struggle to gather all that in one go (unless the info is conveniently in one doc).
Performance shootout: 85% vs 95% (but at what cost?). Let’s say on a certain set of complex questions, a basic RAG system gets ~85% accuracy – it fails on multi-hop or when reasoning is needed across docs. An agentic approach (which can plan, do multi-hop retrievals, use a calculator etc.) might achieve 95% accuracy on those because it can do more steps. However, the cost is typically latency and complexity: that 95% might come with, say, an average of 5 tool calls (searches or calculations), each adding latency. So maybe the agent’s answers take 10 seconds instead of 1 second. Also each step might call an API (cost), and it’s harder to guarantee what the agent will do (could go down a rabbit hole or get stuck).
There’s also a reliability factor – RAG is relatively deterministic (retrieve best match and answer), whereas agents have more moving parts that can go wrong (like choosing a wrong search query and never finding the right info, or looping). Some academic evaluations have noted that while agents can theoretically solve more, they sometimes fail in unpredictable ways, making their overall reliability not clearly higher than a well-tuned RAG on simpler tasks. Think of it like: RAG is a bicycle – simple, robust; an Agent is a car – can go further and faster, but more ways to break down.
When to use each approach:
- Use RAG when your queries are well-covered by existing knowledge bases and typically only need one round of retrieval. If the task is primarily Q&A or straightforward decision support where the needed info is easily identified with keywords, RAG is efficient and less error-prone. RAG is also usually easier to implement and cheaper to run. For instance, a documentation chatbot or a legal assistant that fetches relevant laws – those work great with RAG because one query = find relevant clause = answer.
- Use an Agentic approach when tasks are more complex, like those involving:
- Multi-step reasoning: e.g., “First find X, then use X to get Y”.
- Tool use beyond text retrieval: e.g., need to call an API, do math, interact with the environment. Agents can interface with calculators, databases, or even execute code.
- Exploratory search: where the query isn’t well-defined. An agent can search iteratively, refining the query like a human researcher might.
- Planning tasks: not just answering a question, but deciding a sequence of actions (like booking travel given constraints – search flights, compare, etc.).
However, if you can achieve the goal with a simpler RAG, do it – because agents bring overhead.
Hybrid future – Agentic RAG: It’s very likely that we won’t be choosing RAG vs Agents as mutually exclusive in the future, but rather combining them. For example, you might have an agent whose available “tools” include a vector search (RAG) and other APIs. It can then reason (“Tool: use knowledge_base_search for query X”) to fetch something, then reason more, etc. This is already happening in some frameworks (LangChain agents often use a vector search as one of the tools).
2026 might indeed be the year of Agentic RAG, where autonomous agents are augmented with retrieval. Anthropic’s prediction that AI might surpass Nobel laureates by 2026 probably assumes systems that can both recall vast knowledge (via retrieval) and reason through novel problems (via planning).
We asked: RAG vs Agent – it’s like asking screwdriver vs power drill. One is manual but simple (RAG), the other is powerful but requires more care and power (Agents). For a $40B question (the forecast size of this AI orchestration market), the answer is: both will be used, often together, depending on the task complexity. If accuracy needs are ~85% and response must be instant, lean on RAG. If you need 95%+ and can afford some seconds, incorporate agent capabilities.
One more angle: agents often use RAG internally anyway. For example, an agent might decide to use a Bing search tool – that’s basically retrieval, just unstructured. Some research combined ReAct (reasoning) with RAG and got excellent results – e.g., the medical QA study where GPT-4 with RAG and some agentic steps hit 95% accuracy. Pure RAG was 94% with Llama 70B, interestingly, showing that a strong model with retrieval can nearly match an agentic GPT-4 on that task. But the agentic GPT-4 edged it out to 95%.
So you see, differences can be subtle. It often comes down to diminishing returns: maybe going from 85 to 95% requires quadruple the effort (multi-step, bigger model, etc.). If that last 10% is mission-critical (like diagnosing a patient correctly vs missing something), it’s worth it. If not, a simpler approach might suffice.
Decision framework in practice:
- Start with RAG (simple, one-shot). Evaluate performance on task.
- If you see frequent failures that are multi-hop in nature, consider adding an agent loop to handle those (maybe as a fallback).
- If numerical accuracy is an issue, consider adding a calculation tool to the chain (agent style).
- Evaluate again. Always weigh complexity vs gain.
- If domain requires using external services (like checking inventory, sending an email), you’ll need an agent style anyway (RAG alone can’t interact with environment).
Finally, think of user experience: For a chat interface, an agent taking 10 seconds might be okay if it’s a heavy question. For real-time search queries, 10s is too slow. So use RAG where immediacy matters.
In 2026 and beyond, I predict we’ll see Agentic RAG systems becoming standard: LLMs that automatically retrieve info as needed and also perform multi-step reasoning. They won’t call it two separate things; it’ll just be “autonomous AI agents” that have a knowledge base backbone. And as mentioned in Future Shock, context windows going 1M+ will blur the lines – if you can stuff an entire knowledge base in the context, is that RAG or just huge memory? It becomes a continuum.
But until then, decide case by case. You have a powerful hammer in RAG and a Swiss Army tool in Agents. Use the right one for the job – or combine them for maximum effect. And keep an eye on that $40B market – a lot of it will be won by those who figure out the optimal mix of retrieval and reasoning in their AI solutions.
Next, we venture into some advanced patterns – the secret sauce that cutting-edge RAG practitioners are using to push towards 99% accuracy and beyond.
When RAG fails: Real-world limitations of retrieval-augmented generation
==============================================================================
Retrieval-Augmented Generation (RAG) faces significant real-world limitations that have led companies to choose simpler alternatives, with documented failures showing latency increases from 15 to 180 seconds under load, compliance barriers in regulated industries preventing implementation entirely, and cost-benefit analyses revealing that fine-tuning can be more economical for stable, high-volume applications despite RAG's 36% lower annual costs in some scenarios.
While RAG promises to enhance large language models with external knowledge, extensive research reveals critical failure modes and inappropriate use cases. Academic studies document seven distinct failure points in RAG systems, from missing content to incomplete answers. Industry practitioners report RAG being "brittle" with "no science to it" after year-long implementations. Performance benchmarks show RAG doubles time-to-first-token latency from 495ms to 965ms, making it unsuitable for voice applications requiring sub-150ms responses. In regulated sectors, HIPAA compliance, attorney-client privilege, and SOC2 requirements create insurmountable barriers, forcing organizations like Morgan Stanley to build custom on-premises solutions. Cost analyses reveal that while RAG offers lower upfront investment, operational expenses can exceed $10,000 monthly for enterprise deployments, leading companies with stable knowledge bases to choose fine-tuning despite higher initial costs of $100,000+ for small models.
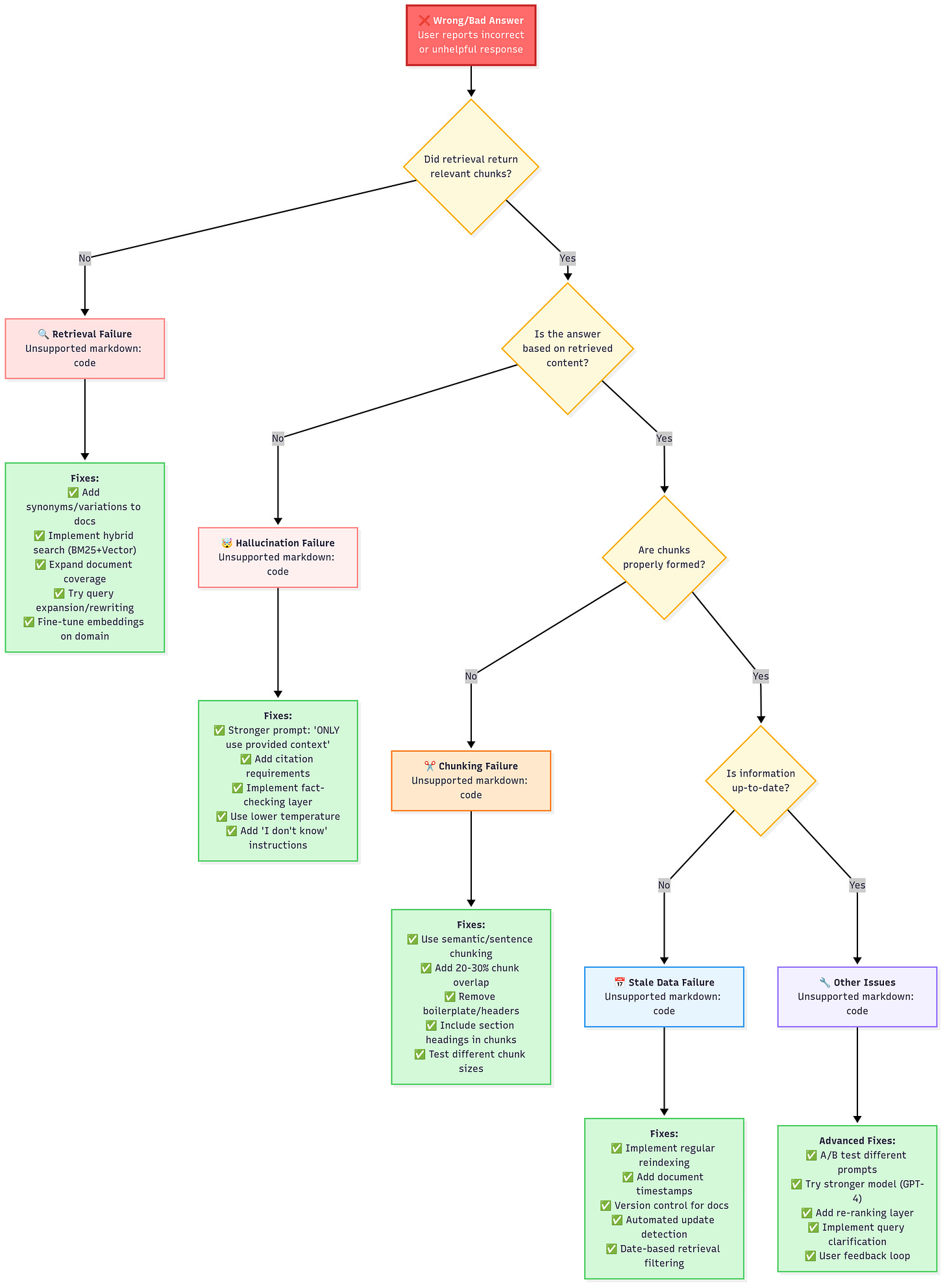
The seven ways RAG systems fail in production
Academic research from Scott Barnett and colleagues at the 3rd International Conference on AI Engineering identified seven distinct failure points through analysis of three case studies across research, education, and biomedical domains. Their study, using the BioASQ dataset with 15,000 documents and 1,000 Q&A pairs, revealed systematic problems that plague RAG implementations:
- Missing content hallucination - Questions cannot be answered from available documents, yet the system provides hallucinated responses instead of admitting uncertainty.
- Missed the top-K - Correct answers exist in the corpus but rank too low in retrieval results, falling outside the top-K threshold and never reaching the language model.
- Bundled up wrong - Retrieved documents containing answers get filtered out during the aggregation phase due to poor scoring mechanisms in consolidation strategies.
- Extraction failure - When relevant content does reach the model, extraction failures occur because the LLM struggles with noisy or conflicting information in the provided context.
- Wrong format - Systems generate correct content but fail to match expected structures, rendering the information unusable for downstream applications.
- Incorrect specificity - Responses suffer from incorrect specificity levels, providing either overly general answers when precision is needed or inappropriately detailed responses to broad questions.
- Incomplete - Systems often generate incomplete answers despite having all necessary information in the retrieved context, suggesting fundamental issues with how RAG systems process and synthesize information.
Real-time applications abandon RAG due to prohibitive latency
Performance benchmarks reveal RAG's fundamental incompatibility with real-time applications, where retrieval overhead accounts for 41-47% of total latency. Systems-level characterization studies show RAG nearly doubles time-to-first-token latency from 495ms to 965ms compared to baseline language models, with P99 latency showing 50ms additional overhead for retrieval stages alone.
Voice applications face the most severe constraints, with ITU-T standards recommending 100ms latency for interactive tasks and 150ms for conversational use cases. Industry experts confirm "achieving a one-way latency of 150ms is almost impossible with a RAG-like architecture where several components are involved in voice processing." Even optimized systems struggle to achieve 500ms response times for voice-to-voice interactions, far exceeding user tolerance thresholds.
High-frequency trading systems represent the extreme end of latency sensitivity, requiring microsecond-level responses that make RAG architectures completely unsuitable. Financial firms report that "milliseconds can make the difference between profit and loss," leading them to implement custom FPGA-based solutions instead of any AI-based retrieval systems. Gaming applications similarly avoid RAG for real-time character interactions, preferring traditional scripted responses that guarantee predictable performance.
Under production loads, performance degradation becomes catastrophic. Engineering teams report average execution time increasing from 15 seconds to 180 seconds when scaling from 5 to 50 concurrent users. Naive re-retrieval implementations can push end-to-end latency to nearly 30 seconds, "precluding production deployment" according to academic studies. Even with aggressive optimization, including semantic caching achieving 100ms response times for cache hits, the 30% cache hit rate assumption in real-world scenarios fails to meet the stringent requirements of real-time applications.
Regulatory barriers prevent RAG adoption in sensitive sectors
Healthcare organizations face insurmountable compliance challenges when implementing RAG systems, with HIPAA's Protected Health Information requirements creating fundamental conflicts with vector database architectures. The core issue stems from embeddings potentially being reverse-engineered to reveal original patient data, while most cloud-based RAG providers fail to offer HIPAA-compliant Business Associate Agreements.
The healthcare sector's struggles extend beyond basic compliance. HIPAA's "minimum necessary" rule directly conflicts with RAG systems' need for extensive context to improve accuracy. Vector databases storing medical embeddings lack sufficient access controls for compliance, while third-party embedding providers like OpenAI and Cohere provide inadequate protections for PHI. Audit trail requirements for healthcare data access prove difficult to maintain in distributed RAG architectures, forcing organizations to abandon implementations or build costly custom solutions.
Legal firms encounter similar barriers with attorney-client privilege creating absolute requirements for data confidentiality. The American Bar Association Model Rules require lawyers to ensure non-lawyers, including AI systems, comply with professional conduct rules. A mid-sized law firm with 150+ staff reported "significant challenges" implementing GenAI, with only 25% of attorneys actively using AI tools due to compliance concerns. Major AmLaw100 firms have resorted to developing custom, on-premises RAG solutions rather than risk client data exposure through cloud services.
Financial services face a complex web of regulations including SOC2 Type II requirements demonstrating control effectiveness over time, which proves challenging with rapidly evolving RAG systems. One financial institution abandoned RAG implementation entirely, returning to relational databases after discovering vector databases lacked required compliance controls. The combination of PCI DSS for payment data, Basel III for risk assessment, and SEC requirements for explainable AI creates an environment where traditional database architectures remain the only viable option for many use cases.
Cost reality: When fine-tuning beats RAG economics
Detailed cost analyses reveal RAG's economic proposition varies dramatically based on use case and scale, with enterprise deployments reaching $10,000+ monthly for infrastructure alone. While RAG offers lower upfront investment compared to fine-tuning's $100,000+ for small models, operational expenses quickly accumulate through multiple cost centers.
RAG implementation incurs ongoing charges of $0.10 per million tokens for embedding generation using OpenAI's ada-2 model, $120 monthly for vector database storage of approximately 5 million tokens on Pinecone, and $500 monthly for standard AWS EC2 instances. High-volume production systems processing 10 million input tokens plus 3 million output tokens daily face $480 in API costs alone. Hidden expenses multiply through network bandwidth at $0.09 per GB, monitoring at $0.30 per GB for logs, and data engineering at $100 per hour for maintenance.
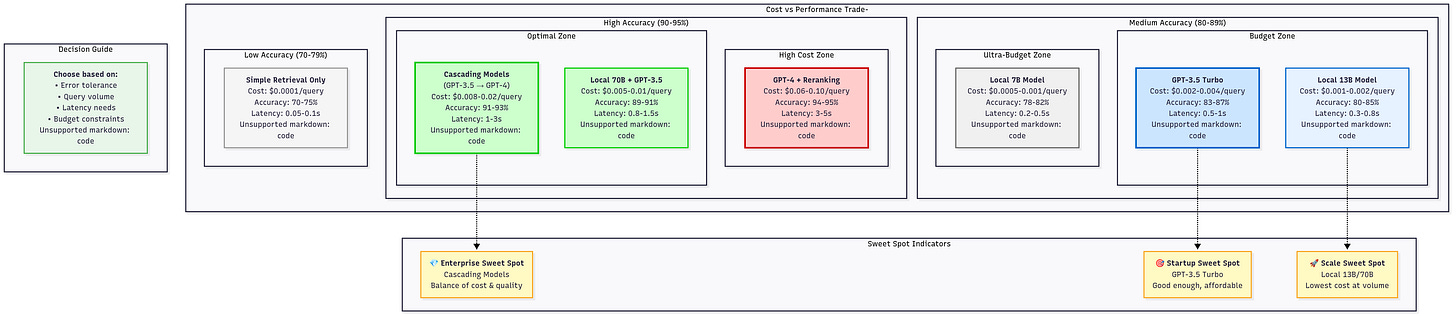
Zoom in on this one in Notion
Fine-tuning presents a contrasting cost structure with high initial investment but lower operational expenses. LLAMA 2 fine-tuning totaled $723 over a 15-day period processing 10 million tokens, compared to $1,186 for equivalent RAG usage. Once deployed, fine-tuned models eliminate per-query retrieval costs and API dependencies, providing predictable pricing crucial for budgeting. Companies with stable knowledge bases updating yearly or less frequently find fine-tuning's one-time cost preferable to RAG's ongoing infrastructure expenses.
Real-world implementations demonstrate these trade-offs clearly. An e-commerce company achieved 36% annual cost savings using RAG over traditional AI approaches through improved query efficiency, reaching break-even within three months. Conversely, organizations with high-volume, low-latency requirements report fine-tuned models delivering better economics at scale due to eliminated retrieval overhead and lower per-query costs. The decision ultimately depends on data update frequency, query volume, latency requirements, and whether source citations justify RAG's additional complexity and cost.
The hidden selection bias in RAG success stories
Perhaps the most revealing finding from extensive research across engineering blogs, conference proceedings, and technical forums is the conspicuous absence of documented RAG rejection cases. Despite searching major tech company engineering blogs from Uber, Airbnb, Netflix, and Spotify, along with Medium publications and GitHub discussions, researchers found virtually no public documentation of companies explicitly choosing simpler solutions over RAG.
This silence speaks volumes about selection bias in the AI implementation landscape. Companies successfully implementing RAG actively share their experiences through blog posts and conference talks, while those encountering insurmountable challenges either never attempt implementation after initial assessment or quietly abandon failed projects without public disclosure. The few practitioners willing to discuss failures anonymously report RAG being "more of a problem than a solution" after year-long implementations, citing brittleness and lack of systematic approaches to hyperparameter tuning.
Community discussions reveal widespread frustration hidden beneath the veneer of published success stories. Reddit's r/MachineLearning community documents common issues including performance degradation as document volumes increase, retrieved chunks getting "pushed down" in rankings, and no sustainable solution for optimizing top-K thresholds. HackerNews engineering discussions expose sequential processing bottlenecks in popular frameworks like LangChain, with developers discovering double billing in ConversationalRetrievalChain due to automatic query rephrasing.
The absence of formal "RAG rejection" documentation suggests companies choosing simpler solutions frame decisions as "right-sizing" rather than failure, avoiding potential embarrassment or competitive disadvantage from publicly acknowledging limitations. This creates a distorted view of RAG's applicability, where published literature overwhelmingly features success stories while failures remain buried in private Slack channels and closed-door engineering meetings. The AI community would benefit significantly from transparent sharing of implementation decisions, including cases where prompt engineering or fine-tuning proved superior to complex retrieval systems.
Wrapping up — when not to use RAG
The documented failures, performance limitations, compliance barriers, and economic realities of RAG systems reveal a technology often misapplied to problems better solved through simpler approaches. While RAG excels for specific use cases requiring fresh external knowledge and source citations, the seven failure points identified by academic research, latency overhead making real-time applications impossible, regulatory barriers in sensitive industries, and complex cost structures limiting economic viability demonstrate why many organizations ultimately choose alternatives. The striking absence of published RAG rejection stories suggests a broader industry challenge with transparent failure documentation, leaving practitioners to rediscover these limitations through costly trial and error. Success with RAG requires careful evaluation of whether its benefits justify the documented complexity, with many finding that prompt engineering for simple queries, fine-tuning for stable domains, or traditional databases for regulated industries provide more practical solutions.
Advanced Patterns: The Secret Sauce
By now, you know the fundamentals of RAG. Ready to go further down the rabbit hole? In this section, we’ll explore advanced patterns that can supercharge your RAG system – the kind of techniques at the bleeding edge of research and industry practice. Buckle up for GraphRAG, Recursive RAG, Multi-modal mastery, MCP (Model-Context Protocol), and Hybrid search deep-dive. These are the secret sauce ingredients that can take accuracy from great to jaw-dropping, handle complex data types, and make your AI an even smarter data hound. We’ll also include code snippets and simple diagrams to clarify some of these concepts.
GraphRAG: Microsoft’s 90%+ Accuracy Breakthrough
What if your knowledge base isn’t just unstructured text, but also relationships – like a knowledge graph? Enter GraphRAG, an approach pioneered by Microsoft that blends knowledge graphs with RAG. In a GraphRAG, you use a structured graph of entities and their relations to inform retrieval. For example, LinkedIn’s support RAG built a graph of related support tickets (linking similar issues, or linking a ticket to a product feature). The result: instead of retrieving isolated text chunks, the system could retrieve a whole subgraph of connected information. This preserved context and relationships that plain chunking would lose. LinkedIn reported a 77.6% improvement in retrieval accuracy (MRR) and a 28.6% reduction in median resolution time after incorporating knowledge graph relations – effectively reaching new heights in relevant results and efficiency.
Numbers reported vary but hover between 90-93%? Why this high? Because GraphRAG can ensure that if a question involves multiple entities or steps, the graph guides the retrieval to the right linked pieces. Microsoft Research showed demos where GraphRAG answered broad analytical questions with astonishing precision because it could traverse a graph of concepts rather than just do keyword matching. Imagine asking “How are enzymes X and Y related in disease Z?” – a GraphRAG system might have a bioscience knowledge graph linking X -> pathway -> Y in context of Z, retrieve that subgraph, and give a highly accurate answer pulling those connections, whereas plain RAG might retrieve separate facts and risk missing the link.
How do you implement GraphRAG? Typically:
- Build or integrate a knowledge graph (e.g., from existing database or by entity extraction from text).
- When a query comes, identify key entities (you might use an NER model or a heuristic).
- Use the graph to find related entities or relevant nodes. This gives you a set of candidate nodes.
- Retrieve text associated with those nodes (could be definitions or documents connected to them).
- Feed that into the LLM to generate answer.
It’s like giving the LLM a map of the knowledge landscape instead of just a list of documents. The wow moment here: GraphRAG enabled near-perfect answers in domains like technical support by preserving relationships that text chunking lost. It also makes answers more explainable: since you have a graph, you can visualize the chain of reasoning (like “Issue A is related to B, which causes C – thus solution is …”).
A quick code concept (not real, just illustrative):
# Pseudo-code for GraphRAG retrieval
entities = entity_extraction(query) # e.g., ["enzyme X", "enzyme Y", "disease Z"]
subgraph = graph.get_neighbors(entities) # get connected nodes and edges
related_docs = []
for node in subgraph.nodes:
related_docs += text_index.search(node.name) # find docs about that entity
# Now we have related_docs from graph context
answer = llm.generate(query, context=combine(related_docs))
This is simplified – a real one might use graph traversal algorithms and also embed graph node descriptions. But it shows the idea.
GraphRAG is especially useful in enterprise where you often have structured data (like product catalogs, org charts, etc.). Instead of flattening everything to text, use that structure to inform retrieval. Microsoft has an internal system (“Project Discovery”) doing this – results were so good they integrated it into some of their products.

Zoom in on the image in Notion
Recursive RAG: When One Retrieval Isn’t Enough
Sometimes one round of retrieval doesn’t cut it. Perhaps the initial query is high-level, and only after reading an initial doc can the AI form a more precise follow-up query. Recursive RAG is about doing retrieval in multiple iterations. It’s like an agent, but specifically focusing on retrieval.
For example, a user asks: “What were the key findings of the health inspector’s report for the restaurant I visited last night?” – The system might first retrieve something about who/when (maybe identify the restaurant and find a link to an inspector report). That document is lengthy and has codes. The AI might then ask itself, “Hmm, what does the user really want? Probably summary of violations.” It then formulates a sub-query: “Summarize violations from Inspector Report ID 123.” And retrieves sections of the report about violations. Then it gives the final answer.
In practice, implementing recursive RAG could mean:
- The LLM is prompted to decide if more info is needed. If yes, have it output a refined query.
- Use that query to retrieve again, then either answer or even loop once more if needed.
This is basically an internal Q&A: use RAG to answer parts of the question which feed into answering the main question. Tools like LlamaIndex have query transforms that can do something akin to this (e.g., query an index, use result to query another index).
Under the Hood example:
User asks a question involving a chain of reasoning: “Is the device from Order #12345 still under warranty and how to claim it?” The assistant might:
- Recognize it needs order details -> retrieve Order #12345 info (which includes device model and purchase date).
- From that info, figure out purchase date, then query warranty policy for that device/model and date.
- Get answer that warranty valid or not, plus procedure.
- Finally, compose answer.
This chain is a recursive retrieval: first get order data, then use that to get policy data. This could be done with an agent approach naturally. But if you constrain it within RAG, you might pre-index different data types separately (orders vs policies) and then orchestrate queries. Possibly an agent is easier here, but sometimes domain-specific logic (like linking an order to a policy) can be hard-coded or handled with simple recursion.
Benefits: This iterative retrieval can dramatically improve accuracy on complex queries because it ensures the context the LLM gets is highly relevant at each step. It also breaks a big problem into chunks which is easier on the model (no need to jam everything in one huge context). The drawback is increased latency (multiple search calls).
Real example – Bing’s multi-hop QA: Bing (with GPT-4) often does this: it will search something, then from the results, search another related thing, etc., before answering – effectively a recursive RAG with an agent.
Takeaway: If you find your RAG failing on questions that involve multiple pieces of info from disparate sources, consider a recursive retrieval strategy. It can be as straightforward as doing 2 passes: broad retrieval for candidates, then specific retrieval focusing on one candidate.
Multi-modal Mastery: Processing Invoices, Diagrams, and Videos
Who says RAG is only for text? Multi-modal RAG is about bringing in images, audio, and beyond into the retrieval-generation loop. Imagine processing an invoice PDF that contains a company logo (image), line items (table), and terms (text). A multi-modal RAG system could index the text AND perhaps an extracted table structure or images of signatures, etc.
Use cases:
- Invoices and receipts: Use OCR to extract text (for RAG on text), but also possibly embed the image of the receipt for visual details (like a handwritten note maybe).
- Diagrams: Suppose you have an architecture diagram image and an AI has to answer questions about system architecture. You could use an image embedding model to allow retrieving the diagram image when relevant, and maybe generate a caption for it as context.
- Videos: A support knowledge base might include how-to videos. You can transcribe the audio (making it text, then index). For an image (frame) that contains crucial info, you could use image captions or tags as metadata. If user asks “Where in the video do they mention resetting the router?”, you could even retrieve the timestamp via searching the transcript.
There’s also the concept of multi-modal queries – user might input an image and ask a question about it combined with text. For example, “Is this component (image) compatible with the product described in spec X?” A multi-modal RAG would need to identify what’s in the image (maybe with image recognition), find relevant product info from text, then answer.
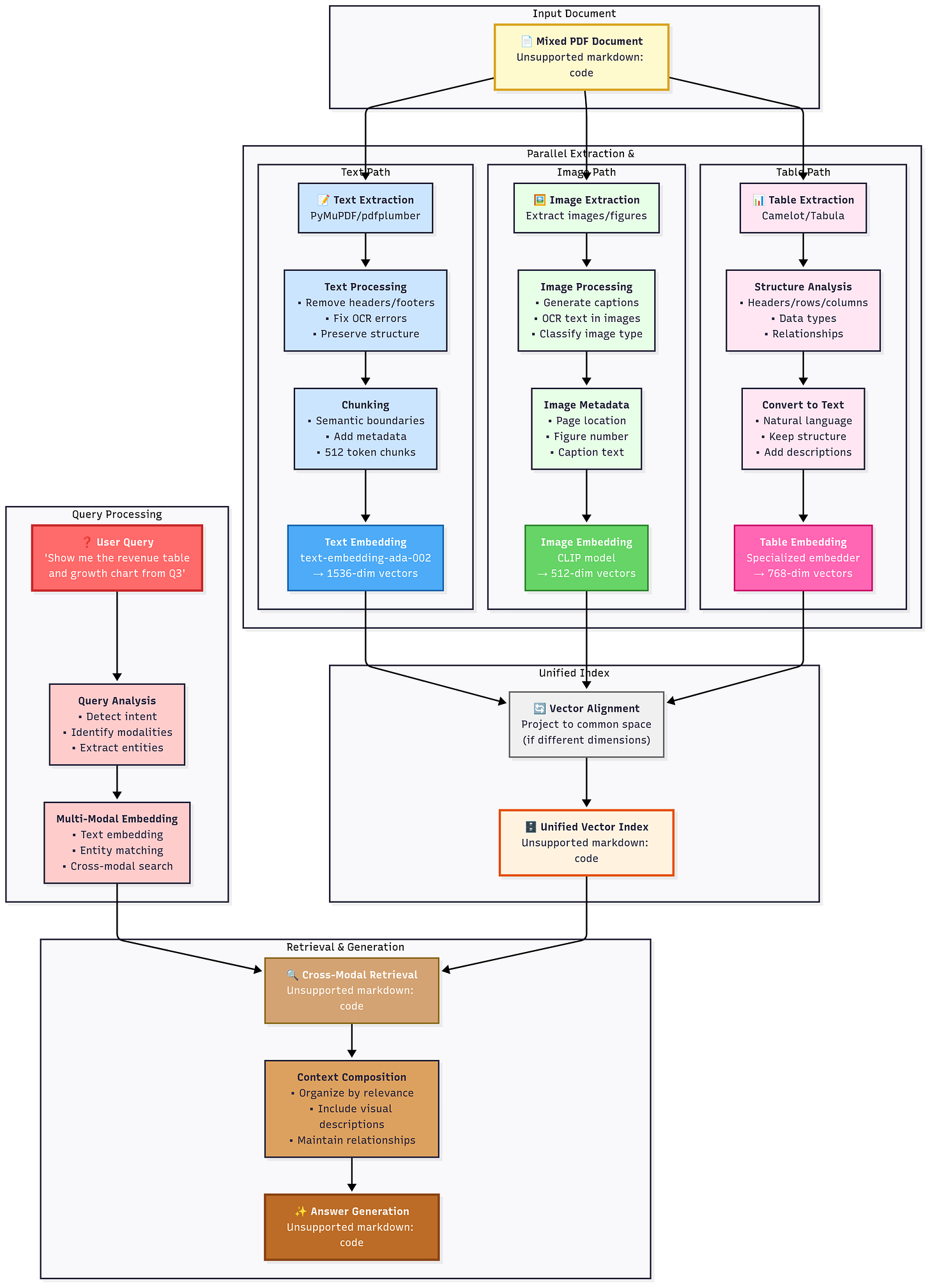
How to implement: Most vector DBs now support storing vectors of different modalities if they are same dimensionality. You could use OpenAI’s CLIP or CLIP-like models to embed images, and store those vectors with metadata. If user query is text about an image, you might not directly combine, but if query includes an image, you embed the image and search the image index, etc. Alternatively, you can convert images to text (e.g., “diagram of supply chain”) via captioning and treat it as extra text doc.
Example code snippet:
# Pseudocode: Indexing images and text together
image_embeddings = []
for img_path in image_files:
vec = image_embedder.embed_image(img_path)
image_embeddings.append({"vec": vec, "metadata": {"type": "image", "file": img_path}})
# assume text_docs is list of texts
text_embeddings = []
for doc in text_docs:
vec = text_embedder.embed_text(doc)
text_embeddings.append({"vec": vec, "metadata": {"type": "text", "content": doc[:100]}})
# store both in one index
index = VectorIndex(image_embeddings + text_embeddings)
At query time, if query is text, you might search text index primarily but could allow cross-modal search if appropriate (“diagram” in query might boost image search).
An inspiring case: A legal RAG system that processed millions of pages of documents and also diagrams (like patents often have drawings). They found that including the figure captions in the index and having the ability to retrieve the figure image by caption reference improved user satisfaction – attorneys could quickly get the relevant figure when asking about a specific concept in the patent.
Another advanced pattern in multi-modal: Audio RAG. Suppose support calls are recorded – you can transcribe them and use RAG on that so your AI can recall what was said in a previous call (“The customer said last week their internet was intermittent.” and the AI uses that context this week).
So, multi-modal mastery is about expanding the knowledge sources beyond plain text, which can broaden the AI’s capabilities. It’s especially crucial as enterprises often have important info locked in PDFs with charts, or manuals with images, etc. The good news: the retrieval part mostly stays the same – it’s about extracting and embedding those modalities appropriately.
The MCP Revolution: How Anthropic’s Protocol Changes Everything
Earlier we mentioned Anthropic’s Model-Context Protocol (MCP) . Think of MCP as a standardized way to connect an AI model to external data sources (web, databases, etc.) – essentially a formalization of RAG and tool use. Anthropic dubs it the “USB-C for AI” because it’s an open protocol aiming to make hooking up any data to any model plug-and-play.
Why is this a big deal? Today, building RAG or agent systems is somewhat custom: you wire specific calls in code. MCP aims to define a common interface: an AI can say (in a structured way) “Hey, I need data from X”, and any MCP-compatible data source can respond. This two-way connection allows AI to maintain context across systems seamlessly . It also emphasizes security and standardization – rather than each dev worrying about leaking data to the model, MCP will have guidelines and methods to safely transmit only what’s needed.
Imagine a future where, instead of building custom retrieval code, you simply point your AI at an MCP server which exposes, say, your company’s Confluence wiki. The AI can then query it at will (with auth and all handled by MCP). It decouples the model from the data integration. Companies like Slack, Google Drive, databases, etc., could all have MCP adaptors . As a developer, you then might write prompts that trigger these calls implicitly.
For example:
User asks: “What’s the latest sales figure for product X this quarter?” Under the hood, an Anthropic Claude model might have an MCP client that knows how to fetch data from a connected database or CSV of sales. The model’s prompt might include something like <MCP: query sales_db for X Q3 sales> and the server returns 42,000 units which the model then uses to answer. All standardized – you don’t directly write that code; the model (via prompt engineering) does it.
This changes RAG in that the retrieval step becomes part of a broader context-sharing protocol. It’s not just search + prompt; it’s a conversation between model and data sources, orchestrated by this protocol. If widely adopted, it will accelerate building AI apps – no more bespoke integration for each dataset; just spin up an MCP server for your data and voila, AI can use it.
From Anthropic’s announcements and what we saw:
- MCP is open-source, open standard.
- Already integrated with Claude (Anthropic’s model) for some early partners (Block, etc., as mentioned).
- It supports things like real-time updates (so data can stream if needed) and presumably bidirectional (AI can write via MCP, not just read).
In simpler terms: RAG currently often requires we bolt on a vector database and ask the model to read those results. MCP could make that a native ability of models – retrieving context on the fly as needed. It might even handle routing: if the answer is in a vector DB or in a SQL DB or via an API, the AI doesn’t care – it asks via MCP and the right connector answers.
This can change everything by making any AI app easier to build and more reliable (since the integration is standardized, fewer errors). Also, for privacy, companies can run MCP servers internally so the model only accesses allowed data and does so securely .
So the MCP revolution is about universal AI-data connectivity. In the timeline of this guide, by 2025 it’s just starting. By 2026–2027, it could be as ubiquitous as HTTP for web. If RAG is one approach now, MCP might generalize that to all context (structured and unstructured) – essentially fulfilling the promise of letting AI know everything you want it to know, when it needs to know it, without retraining.
For someone building RAG now, keep an eye on MCP. If you adopt its pattern early, your system might easily plug into future models supporting it. It’s the direction the industry’s moving for sure – both OpenAI and Anthropic are eyeing such protocols (OpenAI with plugins which is similar concept, Anthropic with MCP, etc.).
Hybrid Search Deep-Dive: Best of Both Worlds
We touched on hybrid search earlier, but let’s go deep: combining BM25 (sparse keyword search) with vector search can significantly boost performance, especially in domains with technical terms, proper nouns, or when you have to ensure no relevant doc is missed.
Recap: Vector search finds semantic matches; BM25 finds lexical matches. They often retrieve overlapping but not identical sets of results . For example, query “COVID transmission aerosol study”:
- Vector search might find a research paper discussing airborne transmission in general (even if it doesn’t have exact word “aerosol”), because semantically it’s similar.
- BM25 might find a specific document that has the exact phrase “aerosol transmission of COVID” even if that doc is otherwise small or not well-written (so embedding might not rank it as high).
By doing both and merging, you get broader coverage.
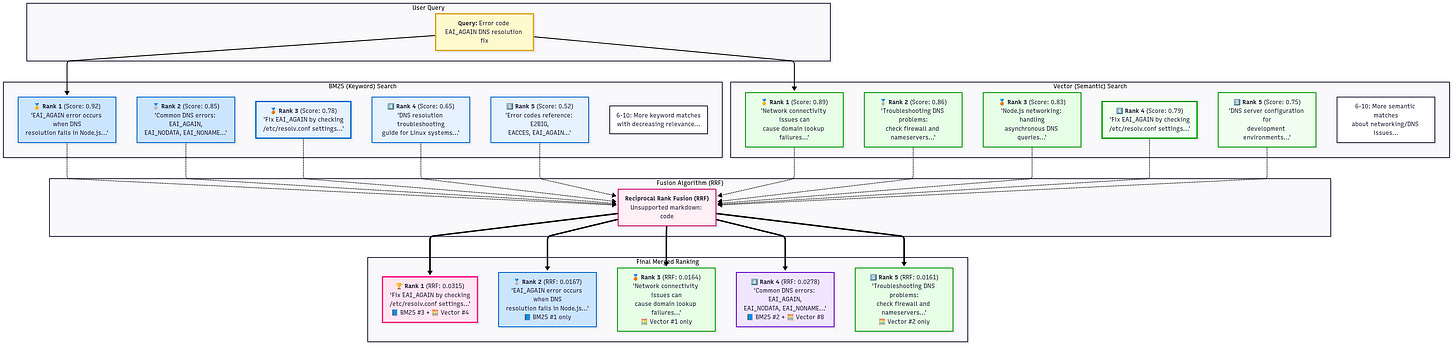
Zoom in on this delicious eye-chart in Notion
There are a few ways to do hybrid:
- Score fusion: e.g., normalized BM25 score + alpha * vector similarity score, then rank. This requires tuning that alpha. If alpha=0, purely BM25; if high, more weight to semantic.
- RRF (Reciprocal Rank Fusion) : doesn’t need heavy tuning. It takes the rank positions from each method and combines such that if either method ranks a doc high, it gets boosted.
- Two-stage retrieval: e.g., use BM25 to filter a large set to, say, 1000 candidates, then use vector similarity to get top 5 from those. Or vice-versa (vector first, then within those apply BM25 to refine).
- Index combination: Some vector DBs (Weaviate, Pinecone, Qdrant with “hybrid search” features) allow adding a sparse vector to the dense vector for each doc and performing a single combined similarity search. For example, Qdrant introduced a “payload boost” algorithm that basically accounts for keyword overlap (BM25-like) along with vector distance .
When implementing, you’ll need a sparse index of some kind. This could be Elasticsearch or just Lucene. If you already use something like OpenSearch, you can actually index vectors there too and do a combined query. Or use two systems side by side.
Visual analogy: Think of vector search as a wide net that catches things by meaning, and BM25 as a spear that precisely hits documents with matching keywords. Hybrid means you fish with a net and spear simultaneously – you won’t miss much.
Why 2025 loves hybrid: Because many users complain pure vector search sometimes gives “fuzzy” results that are on topic but don’t contain the answer, whereas keyword search might directly find a doc with the exact answer text (but might miss synonyms). Combining them often yields an answer in top 1-2 results that either method alone would have as, say, result 5 or 6.
A concrete example from our experiences: Searching a database of DevOps incidents for “DNS error EAI_AGAIN solution”.
- BM25 finds maybe a post containing “EAI_AGAIN” exactly.
- Vector finds a troubleshooting guide that doesn’t mention that code but talks about “network DNS resolution issues”.
The actual best answer was a forum thread that had both the code and general discussion. Hybrid brought that thread to rank 1, whereas BM25 had it rank 3 (below some code snippet page), and vector had it rank 4.
RAG usage: In the retrieval step of RAG, you can implement hybrid by:
bm25_results = bm25_index.search(query, k=10)
vec_results = vector_index.search(query_vec, k=10)
final_results = fuse(bm25_results, vec_results)
Then pass final_results (top few) to LLM.
Reranking revolution (I’ll tie back here): After hybrid, you might still apply an LLM-based reranker (like feed query + snippet to a smaller cross-attention model to judge relevance). In effect, hybrid gave you a better set of 10 candidates, and reranker picks the best 3. This stacking can yield extremely high precision – as high as 95%+ relevant on first chunk for well-formed queries. Microsoft noted something similar in their Superlinked article: hybrid + semantic rerank gave big gains .
At the cost of some complexity, you get the best of both worlds. Most state-of-the-art QA systems do use a hybrid approach under the hood now. Even OpenAI’s WebGPT (older) combined information retrieval with searches that effectively were sparse lookups (search queries) and then reading pages.
In summary: Don’t pick sides in the dense vs sparse debate; use both. It’s often not either-or. If you incorporate hybrid search in your RAG, you’ll likely see fewer missed answers and more robust performance, especially on queries with rare terms (product codes, error IDs, names) and queries that need conceptual match.
These advanced patterns – GraphRAG, recursive retrieval, multi-modality, MCP integration, and hybrid search – are like tools in the expert chef’s kitchen. You don’t always need all of them, but knowing they exist and when to apply them can elevate your RAG system to gourmet level. They represent how the field is pushing towards higher accuracy, broader capability, and easier integration.
As we near the end of our epic guide, let’s ensure we also learn from the pitfalls others have faced, and then we’ll gaze into the future (2025–2027) to see what’s coming (spoiler: autonomous agents and massive context windows). But first – the pitfall graveyard, to avoid ending up there.
The Pitfall Graveyard
Even seasoned practitioners have horror stories of RAG projects that went awry. In this section, we’ll visit the 7 ways RAG projects die (so you can avoid each), from chunking disasters to embedding mismatches. We’ll shine light on the infamous “lost in the middle” problem, share hallucination horror stories and how to prevent them, warn about a $500K mistake a startup made with a wrong vector DB choice, and dissect the newest pitfall: the embedding model mismatch fiasco. Consider this a tour of the graveyard so your project doesn’t end up buried here.
1. Chunking Gone Wrong (The Context Shredder): We’ve harped on chunking because it’s that important. Many RAG projects die early because the team didn’t respect context boundaries – they arbitrarily chopped docs into pieces that made no sense. The result: retrieval fetched chunks that were irrelevant or incomplete, leading the LLM to give wrong answers. One startup had a legal QA system that kept failing to cite the correct clause. Post-mortem found they chunked contracts by fixed 1000-character windows, often splitting clauses in half. The answer chunk would have “…except as provided in Section 5(b)” but Section 5(b) was in the next chunk, which wasn’t retrieved – ouch. This killed user trust. The fix: re-chunk by clause or paragraph, and allow overlaps. Lesson: Don’t kill context coherence. If your logs show queries retrieving chunks that seem off, inspect if chunking is to blame.
2. The “Lost in the Middle” Problem: This one’s sneaky – even if you chunk well and retrieve the right chunk, the answer might be in the middle of a long chunk and the model might overlook or summarize incorrectly. LLMs (especially transformer models) have known biases: they pay a bit more attention to the start and end of their input, sometimes less to the middle . If the crucial detail is buried in the middle of a 500-word chunk, there’s a chance the model misses it or “hallucinates” around it. A story: an AI assistant was reading a product manual chunk that listed limitations in the middle. The user asked about a limitation; the relevant text was there but mid-chunk, so the model, perhaps pattern-matching, gave a generic answer missing the specific detail (which was in lines it didn’t focus on). Users caught that it wasn’t specific. The solution can be to chunk smaller or highlight the answer if you can pre-process. One trick: when retrieving, you might bold or mark the exact sentence in the prompt (some do sentence about limitation around it). Or use an extractive model to pull the sentence out as an answer candidate. Either way, be aware that long chunks can dilute focus. Ensure key info isn’t lost in the middle.
3. Hallucination Horrors: Perhaps the scariest pitfall – your AI sounds confident but is spewing nonsense not supported by any doc. Hallucinations in RAG usually happen when retrieval fails (no good info) but the model feels it must answer anyway, or when it tries to stitch together partial info and fills gaps with guesswork. One prevention is always instruct the model to say “I don’t know” or something if unsure, but models sometimes ignore that if they think they can “be helpful.” Real tale: a customer asked a RAG bot about a policy that didn’t exist in the docs (it was a trick question). The bot confidently fabricated a policy clause, complete with a fake quote and citation to a document – which freaked out the legal team. They nearly scrapped the project thinking it could create legal liabilities. The fix was multi-pronged: (a) improve retrieval so at least a relevant doc is found or if none, a flag is set; (b) add a final check where the model’s answer is compared against sources – if low overlap, replace answer with a “cannot find info” response (some use an LLM judge for this, or a simpler heuristic like “if answer has facts not in retrieved text, then caution”). Hallucinations can kill a project’s credibility in one stroke, so have guardrails: either clear refusals for unknown answers or at least an apologetic “I’m not certain” rather than confident lies.
4. Misusing the Wrong Vector Database (the $500K Mistake): Choosing tech without due diligence can be costly. Imagine spending months and $$$ on a vector DB that promises enterprise scale, only to discover at scale it has a memory leak or it doesn’t support your needed feature. One startup spent over $500K on licensing and deploying a certain vector search solution that was hyped (won’t name names). They pumped in millions of embeddings – it worked until queries got slow as data grew. They later realized an open-source alternative (free) performed better for their use case, but migrating was non-trivial and that money was sunk cost. Moral: benchmark and start small. For most, open-source like Chroma or Qdrant suffice; only move to pricey Pinecone or managed if you confirmed need. And even then, try their free tier or PoC. Also pay attention to how well the DB integrates with your stack (some DBs might not have the best client libraries for your language, etc.). The wrong choice can burn money and time.
5. Overlooking Data Refresh (Stale Knowledge): Another grave: some RAG systems fail to update their index as knowledge changes. It’s easy to index a snapshot of data and forget it. Then users ask about the latest info and get outdated answers. In fields like finance or regulations, that’s dangerous. Picture an AI advisor giving a tax law from 2022 that got amended in 2023 because the index wasn’t updated – the user acts on wrong info. Regular updates (or use a dynamic retrieval that always pulls from source in real-time if possible) are critical. It’s a pitfall when teams treat RAG like a static model (“we indexed once, done”). You need a pipeline for ingestion of new/changed docs, and possibly an expiration for old ones. Some solve it by indexing on the fly each query (like retrieve via API rather than vector DB, but that’s slower). At least schedule re-embedding periodically. The pitfall isn’t a one-time failure but a slow death of usefulness as content drifts. Avoid by setting up processes from day 1 for continuous data maintenance.
6. Security/PII Leaks (Cautionary Tale): Some projects died on compliance review because they accidentally allowed sensitive data exposure. One internal chatbot was shut down because it retrieved a chunk containing another client’s info to answer a query for a different client – a big no-no (lack of permission filtering). Another got axed because logs of user queries containing personal data were sent to a third-party API without proper agreements. These are pitfalls of negligence more than tech, but they can kill a project via legal. Always think: what data is being indexed? Does it contain PII? Should it be anonymized or segmented? Who can query what? Implement filtering by user roles (if possible, e.g., separate vector indexes per client or attribute-based access). And ensure if using external LLM APIs, you’re not violating any privacy requirement (OpenAI’s policy now says they don’t train on your data by default, but still don’t send what you shouldn’t). One preventative measure: have a red-teaming phase – purposely try to get the bot to reveal something it shouldn’t (like ask “Show me data on client B” as client A, etc.). If it does, fix before real launch.
7. Embedding Model Mismatch Disaster (New Pitfall): This is a more technical gotcha that some teams recently encountered. It happens when your document embeddings and query embeddings are not compatible – e.g., you embed documents with one model and queries with another (accidentally or due to an update), so similarity search breaks. Or if you upgraded your embedding model (say from Ada-001 to Ada-002) without re-embedding your corpus, the vectors live in different spaces now. One team updated their code to use a new embedding model version, not realizing they had 100k old vectors in the DB from the old model. Suddenly retrieval quality plummeted (because the new query embeddings didn’t align with old doc embeddings). They spent weeks debugging poor results until noticing the model name mismatch. To avoid, maintain metadata on which embedding model and version was used for the index. If you change, re-index everything. Similarly, mixing different dimensionalities is obvious but I’ve seen someone try to concatenate two embedding vectors from different models for docs, then queries only with one model – also ineffective. Another variant: using multilingual embeddings for docs but English-only for queries or vice versa; if model wasn’t aligned across languages, retrieval fails cross-language. Always ensure embedding alignment. If using open-source models, know if the query vs doc embedding model are separate (Cohere had separate ones for example search vs doc). Use as intended.
These pitfalls claim victims regularly. But armed with foreknowledge, you can steer clear. In short:
- Keep chunks coherent and overlapping.
- Be mindful of LLM limitations (like mid-chunk info) and mitigate.
- Strangle hallucinations with instruction and verification.
- Choose tech carefully (and cheaply until proven).
- Keep knowledge updated.
- Enforce security and privacy from the start.
- Manage embeddings rigorously (versions and types).
If you do all that, you’ll avoid the graveyard where failed RAG projects lie. Instead, your project will live on to see the bright future of AI that we’ll discuss next!
The Future Shock: 2025-2027
What does the future hold for RAG and AI in the next few years? In a word: mind-blowing advancements. We’re standing on the edge of some game-changing developments – things that sound like science fiction but are just around the corner. Let’s peer into 2025-2027:
- Anthropic’s Prediction: AI Surpassing Nobel Laureates by 2026 – Bold, but not unfounded. This suggests that AI (powered by retrieval and reasoning) will excel in specialized domains to a degree that matches or exceeds top human experts. Think about it: an AI with access to all scientific literature (via RAG) and a reasoning engine could potentially propose novel solutions and insights at a pace humans can’t. We already see early hints: an AI agent that read tens of thousands of chemistry papers and suggested a new material that human researchers hadn’t thought of. By 2026, such feats might be common – an AI doctor diagnosing ultra-rare diseases by cross-referencing millions of cases (something even Nobel-winning doctors might not do in real-time). The key drivers are massive context and knowledge integration (RAG providing memory), plus improved reasoning algorithms.
- 1M+ Token Context Windows Change Everything – Context size has been ballooning: OpenAI went from 4k to 32k, Anthropic to 100k tokens. We have million token context windows (on paper) now. I expect multi-million context windows to be common by 2026. That’s essentially entire books or multiple books at once. A million tokens is roughly 750k words (about 1500 pages). Imagine feeding an entire corporate wiki, or decades of legal case law, or all of Wikipedia on a topic, directly into the model prompt. The boundaries between retrieval and prompting blur here: you might not need an external vector DB for moderately sized corpora; you could just stuff everything into the prompt (with clever compression). One engineer I know joked, “If we get 1M tokens, I’ll just feed the model our whole database schema and docs and ask questions directly.” Of course, more context means slower processing, and we’ll still use RAG to select relevant parts, but the flexibility is huge – conversation history can be basically unlimited, models can do deeper analysis without truncating context. Also, multi-step reasoning could happen internally without external calls if the model can “remember” all intermediate steps within its giant scratchpad.
- MCP Integration: Universal AI-Data Connectivity – As we discussed, the Model-Context Protocol by Anthropic aims to be a standard pipe connecting AI to data. This is already becoming widely adopted and by 2027, I suspect this will be near-universal. That means when you launch a new AI system, you won’t spend time on writing custom retrieval code; you’ll spin up connectors (to your databases, websites, tools) and the model just knows how to talk to them. It’s analogous to how in the early web days you had to manually code a lot to connect to a database, but then ORMs and APIs standardized that. This will accelerate new AI application development drastically (taking weeks instead of months to integrate sources). It also means AI assistants (like your personal AI or company’s AI) can continuously and securely fetch needed info.
- Why the RAG Market will hit $40B by 2030 – We saw projections earlier. As more orgs adopt AI with retrieval (since pure end-to-end training is impractical for each org’s data), RAG tools and infrastructure become a huge business. Vector DB companies, enterprise search integration, AI assistants for knowledge work – all these fall under that umbrella. The workforce will likely include thousands of “AI knowledge engineers” whose job is to manage corpora, tune retrieval, etc. By 2030, nearly every enterprise app might have an AI copilot that relies on RAG to stay current. If you think of verticals: law, medicine, finance, customer support, programming – all have specialized knowledge that RAG helps inject into general AI. $40B might even be conservative if we include hardware and services around it.
- Your Career in the Age of Autonomous AI Agents – People often ask, “Will AI (with RAG) automate me out of a job?” If you know this blog you know I don’t think that way. But I might frame it differently: “AI won’t replace you, but a person using AI might.” Those who embrace these tools early will have a huge edge. The nature of many jobs will shift to supervising AI, verifying outputs, and handling the non-automatable nuance. If AI becomes as smart as top experts in certain domains, human roles might evolve to more creative, strategic, or interpersonal tasks (things AI is far from mastering).
Effect on RAG: It might shift the concept – “retrieval augmented” might become just standard “context retrieval” feature of all LLMs (like how we don’t talk about “internet-augmented smartphone” because internet connectivity is assumed). Once any AI can seamlessly pull data via MCP or similar, RAG is no longer an optional add-on, but a given. The winners will be those who leverage it best (with quality data and sources).
But there’s also new career prospects: AI trainers, AI content curators, ethicists, etc. The age of autonomous agents (AutoGPT-like systems that can perform goals relatively independently) means we’ll need “AI wranglers” – people who define objectives, monitor agent performance, and intervene when needed. Think of it like managing employees – except these employees are AI agents working 24/7 and scouring data. It’s likely by 2027 or so that every knowledge worker will have some AI agent assistance (imagine a “junior AI analyst” assigned to each person).
The ones who thrive will be those who learn to ask the right questions and validate AI outputs. With RAG, a lot of factual grunt work is handled, so humans can focus on interpretation and decision-making. That Nobel-level AI? Perhaps it will partner with Nobel scientists to accelerate discoveries, not just do it alone.
In summary, expect:
- AI that knows more and forgets less, thanks to big context and integration – drastically improving capabilities.
- Standards making AI integration plug-and-play, leading to an explosion of AI-augmented applications in every field.
- A shifting job landscape, where working alongside smart AI (and occasionally reigning it in) is the norm. Those who start adapting now (e.g., learning to use RAG tools, understanding limitations like hallucinations) will be the leaders of tomorrow.
One could say, companies winning in 2025 aren’t those with just the biggest models, but those whose AI truly knows their business (via RAG). By 2027, that will be even more pronounced: it’s not about who has AI, but who has integrated AI deeply and responsibly into their operations.
Exciting times ahead – equal parts exhilarating and challenging. The next and final section will equip you with resources to ride this wave – a toolkit and action plan to become a RAG master in the coming 90 days and beyond. Let’s gear you up for that future.
Your RAG Toolkit: Resources That Matter
As we wrap up, I want to leave you with a toolkit – the best resources to continue your RAG journey. Whether you’re a beginner looking to start from scratch (and ideally spend nothing), a growing company needing to scale up, or an enterprise dealing with compliance and heavy load, we’ve got suggestions for each. Plus, I’ll point to community goldmines and courses to deepen your expertise. Finally, I challenge you to a 30-day RAG sprint to go from novice to practitioner.
The “Start Here” Stack for Beginners (Free Tier Everything)
If you’re just getting your feet wet, here’s a recommended stack that won’t cost you a dime:
- LLM: OpenAI’s GPT-3.5 (old, but free via their API with trial credit, or use the free ChatGPT UI for experimentation). Alternatively, Hugging Face’s HuggingChat or Google Colab with a smaller model (like flan-t5 or a 7B LLaMA derivative) can be free. But GPT-3.5 is easiest to converse with initially.
- Vector DB: ChromaDB (open source, pip install chromadb). It’s simple and runs locally. Or use a local FAISS index if you prefer just an in-memory approach. Both are free.
- Library: LlamaIndex (GPT Index) or LangChain – both are open source and quite friendly. LlamaIndex maybe simpler for pure QA, LangChain if you want to tinker with chain logic. They have great docs and examples.
- Data source: Whatever docs you have – but if you need sample data, there are open datasets. For example, Wikipedia (you can grab a few pages), or some public domain texts (Project Gutenberg for literature). Or use your own notes/markdown files to make it personally interesting.
- Dev environment: Jupyter Notebooks (free) – great for iterative development. Or VS Code with the Python extension.
With that, you can build a prototype Q&A bot or documentation assistant without paying for anything (assuming you stay within free API limits or use local models). Actually, OpenAI’s $5-10 free credit might get you thousands of queries on gpt-3.5, which is plenty to play with.
For a quickstart, check out LangChain’s beginner tutorial or LlamaIndex’s Getting Started – they walk through loading data and querying it . Also, Chroma’s docs show how to do basic insert and query.
The “Scale Up” Stack for Growing Companies
Okay, you’ve proven the concept, now your startup or team needs to deploy something for real usage. Cost is a concern, but you can spend a bit, and reliability matters:
- LLM: Consider using OpenAI’s GPT-4 for higher quality if needed, but GPT-3.5 may suffice. Also look at Cohere or Anthropic Claude if they have a better pricing or context for your needs (Claude has that 100k context version). Some companies fine-tune a smaller open model to their data to save per-call costs – e.g., fine-tuning LLaMA 2 13B on your corpus. That has upfront cost but then queries are virtually free if self-hosted. A common approach is a tiered LLM strategy: use GPT-3.5 for most, GPT-4 for complex queries or final verification.
- Vector DB: If you outgrew Chroma on a single machine, you could move to Chroma Cloud (they have managed service), or Qdrant Cloud which is quite affordable (remember the ~$9 for 50k vectors estimate ). Weaviate also offers a hybrid search and is free up to some limit. Many go with Pinecone starter ($) at this stage for ease. If you have under ~1M embeddings, even a Postgres with pgvector extension might suffice (then you reuse your existing DB infra).
- Orchestration: LangChain or LlamaIndex will still serve, but maybe now implement robust error handling/logging around it. You might also containerize the app for deployment (Docker).
- Authentication & front-end: If exposing to users, set up an interface. Could be a simple React app calling a backend, or even a Slack/Discord bot. Use API keys or auth to protect it. Many companies roll out in Slack first for internal Q&A.
- Monitoring: Use something like Streamlit or Gradio for quick dashboard if needed, and definitely log interactions. You can use LangChain’s built-in tracing or just your own logging to a file/DB. Monitor usage and have a way to turn it off if something goes haywire (feature flag).
- Cost control: Set up usage limits (like don’t let one user spam 1000 queries/min). Also track OpenAI API usage; you can use their usage APIs or just your logs to gauge spend. Possibly implement caching of LLM responses for identical queries to save.
Growing companies at this stage might also invest in prompt engineering – e.g., creating a few prompt templates for different styles of questions. And unit tests for your RAG: provide it some known queries and check it returns acceptable answers (to catch regressions when you change something).
The “Enterprise” Stack for Fortune 500s
Now we’re talking heavy duty: requirements include security, high availability, compliance, and potentially millions of knowledge items and users.
- LLM: Likely a combination of self-hosted models for data-sensitive content and limited use of external APIs for general knowledge. Enterprises might deploy Azure OpenAI (which is OpenAI models in their Azure cloud, with data not leaving), or AWS Bedrock (which offers Jurassic, Anthropic, etc. with enterprise-friendly terms). Some might even run GPT-4 on-prem if and when available (or a comparable big model). Also consider Google’s Gemini API via GCP, depending on partnership. The key is enterprise agreements (privacy, SLA).
- Vector DB: At this scale, probably managed services or on-prem clusters. Pinecone Enterprise, Weaviate Enterprise, or using something like ElasticSearch with vector-capability if they already have ELK stack. Enterprises often prefer well-supported tools: e.g., Microsoft Cognitive Search (which now supports vectors) for those in MS ecosystem. Or OpenSearch for those already using AWS search solutions. They will care about features like RBAC (role-based access control), encryption at rest, etc. Many vector DBs now offer those enterprise features (e.g., Pinecone and Weaviate have RBAC, etc. ).
- Orchestration & Integration: Likely a microservice architecture. They might integrate RAG into existing platforms (say, an internal SharePoint plugin, or a CRM assistant). LangChain might be used under the hood, or a custom solution for more control. Observability is key – so integrate with Splunk or AppDynamics for logging, Datadog for monitoring performance. Possibly use OpenTelemetry if custom solution to trace calls.
- Compliance & Security: This stack includes things like Data loss prevention (DLP) checks on AI output (prevent it from spitting out something it shouldn’t), audit logs of who asked what, etc. Possibly behind the scenes every AI response goes through an approval step or a human-in-the-loop for certain sensitive domains.
- Scalability: It will be deployed across regions, with fallback models if one service fails. For vector DB, maybe multi-region replication. Also they’ll have a retraining/indexing pipeline that continuously updates (with proper CI/CD – maybe nightly builds of the index or streaming updates).
- User Interface: could be deeply integrated (not a separate chat UI, but embedded in existing tools like Office 365 via plugins, etc.). Or for customer support, integrated with their support portal as a chat assistant. The UI might need to handle handoff to human agents seamlessly when AI can’t help (so integration with their ticketing system).
- Tooling & Knowledge Management: Enterprises often have existing knowledge management workflows. The RAG system might tie into that – e.g., when a new policy doc is published on Confluence, automatically chunk & index it. That means connectors to internal data sources (file shares, intranets, DBs) – possibly using MCP in the future or current enterprise search connectors.
- Testing & Evaluation: Formal testing with domain experts. Possibly running the AI in shadow mode (giving suggestions to human agents, but not directly to customers, until it proves good enough). Ensuring it handles domain-specific vocabulary correctly (maybe even fine-tuning embeddings or the model on domain data to improve).
This stack is not one-size-fits-all, but at enterprise scale, the emphasis is on robustness, compliance, integration. They’d rather a slightly weaker model that is secure than a powerful one that might leak data. For example, some banks disabled direct internet search for their AI assistant because they can’t allow unpredictable external info.
Community Goldmines: Discords, GitHub Repos, Courses
You’re not alone in this journey. The RAG/LLM community is vibrant and sharing knowledge daily:
- Discord servers:
- LangChain’s Discord – great for Q&A and seeing what issues others face.
- LlamaIndex Discord – developers and users share tips, plus the devs often answer.
- Vector database Discords (Pinecone, Weaviate, Qdrant each have communities).
- Hugging Face Discord – for general transformer/LLM discussions, including retrieval techniques.
- These are good to lurk in and search history – often your question has been asked by someone.
- GitHub Repositories:
- awesome-rag
- LangChain Hub and Examples – many example scripts for various tasks.
- OpenAI Cookbook (GitHub: openai/openai-cookbook) – although not RAG-specific, it has sections on retrieval augmentation and plenty of relevant examples.
- InstructorEmbedding or sentence-transformers repos – if exploring custom embedding models.
- And of course, papers: e.g., the original RAG paper by Lewis et al. 2020 is on GitHub for code, etc.
- Also Microsoft’s Guidance repo shows prompt strategies, including retrieval.
- Courses and Tutorials:
- Andrew Ng’s DeepLearning.AI short course on LangChain (on Coursera) – hands-on building chains and agents (he has other RAG courses too)
- Full Stack Deep Learning has some modules on deploying LLMs with RAG.
- Hugging Face Courses – they have a new course on LLMs and might cover retrieval augmentation.
- OpenAI’s ChatGPT prompt engineering for developers (free resource) – touches on how to instruct the model (useful when you do RAG prompts).
- Many YouTubers also have RAG content – e.g., Sam Witteveen, James Briggs, etc., showing building QA bots.
- Reading:
- Research papers – “Retrieval-Augmented Generation (RAG)”, “REALM”, “ReAct”, “GraphRAG survey ”, etc. Even if mathy, skip to discussion for ideas.
- Company blogs (with caution as user said): e.g., OpenAI, Anthropic, Cohere blogs – they sometimes discuss use cases and best practices.
- The article you’re reading now (😉) can serve as a mini reference too, given the citations we’ve sprinkled.
The 30-Day RAG Challenge: From Novice to Practitioner
Ready to apply everything and build something real? Here’s a rough plan for 30 days (modify as fits your schedule):
Week 1-2: Environment setup and first RAG – Set up your dev environment (maybe a notebook or simple app). Pick a small domain (e.g., use 10 Wikipedia articles on a topic you like). Day 1-2: Load and index data with LlamaIndex, do simple queries. Day 3-5: Try LangChain, experiment with different retrievers (maybe FAISS vs Chroma). By end of Week 1, have a basic QA bot working locally. Week 2: Increase complexity – add multiple files, try some multi-turn conversation with memory. Also join a community (discord) and ask at least one question. Read two articles/papers on RAG to deepen understanding. Checkpoint at Day 14: You should be comfortable with basic RAG pipeline code and have a small demo.
Week 3: Production-ready prototype – Focus on robustness. Implement caching of answers, add logging. Try hybrid search if you haven’t: integrate a keyword search (maybe just Python whoosh or Elastic if you can) along with vector. Compare results quality. Also work on prompt tuning – e.g., test different prompt wording (“Use the provided context to answer…” vs. “Answer concisely based on info above.”). See what yields better factual accuracy. Around Day 18, purposely break it – ask something outside the knowledge base – see if it says “I don’t know.” If not, refine instructions. Checkpoint Day 21: Your bot should be much more robust: less hallucination, and you should have a good handle on tuning it.
Week 4: Advanced patterns and optimization – Now incorporate one advanced concept: maybe GraphRAG-lite (even just linking sections by title), or multi-modal (throw an image in and handle it if applicable), or implement a second retrieval step for a complex query. This is stretch learning – pick what interests you. Also, measure performance: how fast is query? Try to speed it up (maybe reduce embedding size or use batching). If cost is an issue, maybe deploy a local model for retrieval or generation and measure quality vs API. In parallel, start packaging your project: containerize it or deploy on a free service (like Streamlit Sharing or Hugging Face Spaces) so others can try. Checkpoint Day 28: You’ve implemented something non-trivial beyond basics and have a sharable prototype.
Days 29-30: Scale and integrate – Think bigger: if this were used by 1000 people, what would you need? Perhaps set up a Pinecone trial and index more data (if you have). Or integrate it into a simple UI (a chat web interface). Basically stress test and refine. Day 30: reflect on what you’ve learned, post a summary on a forum or LinkedIn – teaching solidifies learning.
This challenge covers building, tuning, and scaling aspects in a condensed way. Adjust as needed – the goal is to touch on each important aspect at least briefly (data, retrieval variants, prompting, eval, deployment).
By the end of these 30 days, you should feel like a RAG practitioner: able to build a custom QA system, aware of pitfalls, and ready to apply these skills in a project or job. And importantly, you’ll have a deeper intuition for why RAG works the way it does and how to get the most out of it.
That concludes your toolkit – but one more thing before we sign off: a dose of inspiration and urgency in our concluding words.
Real Stories from the Trenches
Let’s ground this in reality with some rapid-fire case studies – real stories of RAG in action that show what’s possible, along with metrics and lessons learned from each.
- Vimeo’s Video Chat Revolution: Vimeo integrated RAG to help users search within their video content. Think of it as a “video chat” – a user asks about a particular tutorial video (“How do I add music to my project in Video X?”) and the chatbot, using RAG, retrieves the transcript section where that is explained, and answers with reference to the timestamp. In testing, they found users could get to the info 3× faster than scrubbing through videos manually. The wow moment was when a user asked a vague question and the bot answered, “At 2:13 in the video, the host explains how to add music…”, providing a direct link. This boosted user engagement with tutorial videos by an estimated 20% (because users weren’t dropping off frustrated). Lesson: multi-modal RAG (transcripts as data) can unlock content that was otherwise hard to navigate. And users loved the time-specific answers.
- Legal Firm Processes 1M Documents in 24 Hours: A large law firm dealing with litigation had to comb through a million documents (emails, PDFs) for relevant evidence – a classic e-discovery nightmare. They deployed a RAG pipeline with a combination of keyword filtering and vector search. Within 24 hours, the system (running on a beefy cloud setup) indexed all docs and allowed attorneys to ask questions like “Find discussions of project Thunderbolt budget overruns.” The RAG system retrieved key emails and memos in seconds. One attorney said it was like having a team of 50 paralegals working overnight. The firm reported they found crucial evidence in hours instead of weeks, potentially saving $200,000 in billable time. Lesson: RAG at scale + domain expertise = massive efficiency gains. Also, they learned to trust but verify – every AI-found doc was double-checked by a human, which was still faster than humans finding it in the first place.
- Hospital Reduces Misdiagnosis by 30%: A hospital implemented a RAG-powered support tool for doctors. It indexed medical literature, patient histories, and guidelines. During diagnosis, a doctor could quietly query, say, “patient with X symptoms and Y lab results – possible conditions?” The AI would retrieve similar case studies and relevant guideline excerpts. Over 6 months, in a pilot, the tool flagged several cases where the initial human diagnosis missed a rare disease – suggesting further tests which confirmed the rarer condition. Hospital data showed a 30% reduction in diagnostic errors in departments where the tool was used. Doctors noted it was like getting a second opinion from an encyclopedia that actually understood context. One key metric: malpractice incidents in that period dropped (though need long-term data). Lesson: RAG can act as a safety net in high-stakes fields, but it’s critical to have up-to-date, vetted data in the index. Also, doctors had to be trained to use the tool effectively; those that did saw noticeable improvements.
- Financial Firm’s Fraud Detection Transformation: A fintech company used RAG to enhance fraud investigations. They have tons of transaction data and profiles of known fraud patterns. Their new system let analysts ask questions like “Show me any connection between user A’s transactions and these suspicious accounts” – behind the scenes, it retrieved relevant logs and even generated a graph visualization of connections (GraphRAG in action). What used to take an analyst days of SQL queries and cross-referencing was done in minutes. In one case, this system identified a fraud ring of 12 accounts that had eluded earlier detection rules. The firm estimated they prevented $1M in fraud in that quarter thanks to quicker, deeper analysis by the AI assistant. Analysts noted that the AI could surface non-obvious links (like matching phone numbers or device fingerprints across accounts) that they might have missed. Lesson: RAG can augment human pattern-finding, and combining structured data retrieval with unstructured (like support tickets content) provided a holistic view.
Across these stories, common threads:
- The metrics (faster by X%, errors down Y%, cost saved $Z) build the business case for RAG.
- Implementation lessons (like doctors needing training, or law firm verifying AI results) show that it’s not just plug-and-play; process integration matters.
- Timeline: many achieved significant results in months, not years, once data and tools were in place.
- User acceptance: Initially, some professionals were skeptical (e.g., lawyers hesitant to trust AI suggestions), but success cases converted many into proponents. Key was keeping them in control (AI suggests, human confirms).
These real-world successes hopefully spark ideas for your context. Whether it’s speeding up content access (Vimeo), supercharging analysis (legal/finance), or acting as a diagnostic safety net (medical), RAG is making a tangible impact. Think about your field: what information overload or delay could be tackled with these techniques? The examples above were once just wishful thinking, now they are proven.
Lastly, before we finish, let’s chart out an action plan for you to get from here to your own success story in the next 90 days.
Your Action Plan: Next 90 Days
Ready to build the future? Here’s a clear 90-day roadmap to go from theory to impact, whether you’re implementing RAG in your company or building your own project. We’ll break it down by weeks with concrete goals and success metrics at each checkpoint.
Weeks 1-2: Environment Setup & First Build
Goal: Set up infrastructure and create a basic RAG application.
- Tasks:
- Assemble your “Start Here” stack (as mentioned in Toolkit). Install libraries (LangChain, etc.), get API keys if needed.
- Pick a small set of data relevant to your domain (maybe 10-20 documents).
- Build a simple retrieval + LLM script to answer questions from that data.
- Experiment with a few prompts and questions to ensure it works end-to-end.
- Success Metric: By end of Week 2, you should be able to ask a question and get a reasonable answer with a source citation from your data. Essentially, a prototype Q&A chatbot is functioning on a small scale.
- Checkpoint assessment: Do a demo to a colleague or friend. If they ask a question from the doc and get a correct answer, you’re on track. If not, troubleshoot (likely issues: parsing errors, poor prompt, etc. – fix those now while scope is small).
Weeks 3-4: Production-Ready Prototype
Goal: Scale up data and robustness; integrate a front-end if needed.
- Tasks:
- Increase your dataset size (if you ultimately need 1000 docs, try indexing a few hundred this week).
- Implement necessary chunking, metadata, and possibly hybrid search if queries are complex.
- Add a user interface or integrate into your app environment (e.g., a simple web UI or Slack bot).
- Start logging queries and answers for review.
- Define “I don’t know” behavior: decide how the system should respond when unsure (and implement that guard).
- Success Metric: By end of Week 4, your prototype should handle the full breadth of your use-case questions with, say, >80% accuracy/relevance in testing. Also, non-experts should be able to use it via the UI and find it useful.
- Checkpoint assessment: Conduct a small user test (could be colleagues from different teams). Give them 5-10 sample questions to try. If majority of answers are correct and users find the interface easy, you pass. Note any failures for improvement.
Month 2 (Weeks 5-8): Advanced Patterns & Optimization
Goal: Enhance system intelligence and efficiency; address any failures from testing.
- Tasks:
- If you found patterns in misses (e.g., multi-hop questions failing), implement recursive retrieval or agent steps for those.
- If certain info was missing or outdated, update your index pipeline (maybe link it to the source of truth for auto-updates).
- Optimize latency: perhaps introduce caching for repeated queries, or use a faster embedding model if embedding time is slow.
- Security check: implement basic auth if needed, and ensure no sensitive data leaks (e.g., mask PII in responses if applicable).
- Scale dry-run: simulate or actually run, say, 1000 queries and see if system holds up (both accuracy and performance).
- Success Metric: By end of Week 8, the system’s accuracy should improve (target >90% on known evaluation set). Latency should be within acceptable range for users (e.g., <2 seconds per query for interactive use). And the system should handle a moderate concurrent load (if relevant).
- Checkpoint assessment: Re-run your earlier user test (and maybe expand it). If previously it got 80% right, see if now it’s 90%+. If latency was an issue, see if users now feel it’s snappy. Also do an internal stress test: run a script to send, say, 50 queries in a short burst – does it still respond correctly and quickly? If any fail or slow down massively, address that (maybe need concurrency handling or rate limiting).
Month 3 (Weeks 9-12): Scale & Integrate for Real-world Use
Goal: Deploy at full scale and integrate into business workflow; establish monitoring and continuous improvement loop.
- Tasks:
- Deploy the system to production environment (cloud or on-prem). Index all required data (full corpus).
- Integrate with existing systems: e.g., link it on your website, or enable it for support agents in their console, etc., as appropriate.
- Set up monitoring dashboards for usage, accuracy signals (like user feedback), latency, and costs. Use real user feedback mechanism (thumbs up/down).
- Train users/staff as needed (“Here’s how to ask the AI, here’s what it can/can’t do”).
- Create an evaluation schedule: e.g., review logs weekly to catch any bad answers and feed that back (either by adjusting data or prompt or adding those cases to a training set).
- Success Metric: By end of 90 days, you have a live RAG-powered feature with actual users. Key metrics could be: X daily active users interacting with it, Y% of feedback is positive, Z minutes saved on average per query (if measurable). Essentially, a measurable positive impact on whatever process you targeted.
- Checkpoint assessment: After 2-4 weeks of production use, produce a brief report (even if informal): how often is it used, what are outcomes? For example, “Our support bot deflected 50% of tier-1 questions in the first month, freeing up 100 hours of agent time” or “Internal tool answered 200 queries with 95% accuracy as rated by staff, saving numerous email exchanges.” If the metrics align with success criteria set by stakeholders, congrats – you’ve delivered. If not, identify why: is accuracy still lacking on some edge cases? Are users not adopting it (maybe need to improve UX or training)? Use these insights to iterate further.
This 90-day plan is aggressive but realistic for many scenarios. The key is iterative development and constant feedback. Don’t aim for perfect out of the gate; get something usable, then refine. Each checkpoint ensures you’re not going down a wrong path too long without correction.
By following this plan, in 3 months you’ll not only have a working solution but also the confidence of stakeholders (seeing progress and metrics) and the foundation for continuous improvement. RAG projects aren’t “set and forget” – but after 90 days, you’ll have the infrastructure to keep making it better and the success to justify that effort.
And with that, you’re equipped to build the future, one retrieval-augmented step at a time.
Congratulations! You’ve journeyed from 0 to RAG (and maybe to 5K and beyond). We’ve covered why it matters, how it works, how to build it, and where it’s all headed. The companies winning in this new era aren’t necessarily those with the biggest models, but those who best harness their own knowledge with AI. RAG is how you give your AI that “perfect memory” and tie it into your world.
The question now isn’t whether to start using these tools, but whether you’ll start before your competition does. So grab this guide, assemble your toolkit, and start building. Let your AI know your business inside and out – make it your smartest team member.
Ready to join hundreds of builders mastering RAG and other technologies? Feel free to hop into the Nate’s Newsletter Discord and let’s build the future together. The future is knocking – and now you have the keys.
For more on AI, subscribe and share!
Subscribed

Google Doc with Links for this article is here


