Inspired by the fairy tale, I put together a guide to Goldilocks prompting, a new technique focused on short (<500 token) prompts that steer the model to 10x your power to get useful work done
Nate

Goldilocks prompts are something I’ve never written about before.
They sound really simple: not too long, not too short, just like the fairy tale.
What’s the big deal?
Well, first they’re incredibly powerful at getting the model to change behavior and do useful work, and second they’re MUCH harder to write than they look.
Why so hard? Because Goldilocks prompting is not about length. It’s actually about deciding how much space your AI gets to make its own decisions when following your instructions. Think of it freedom: these prompts shape how much freedom the AI gets to pursue a task.
Just like the fairy tale, you have three options:
- Write a very short prompt (just a line or two) like: Do an analysis of these bank statements. Follow best practice. Well, the AI has a lot of freedom there doesn’t it? It can do pretty much anything it wants. You haven’t told it what you want, and you’ve assumed a lot of shared context along the way.
- Write a very long prompt: 10 pages of specifications with 18 ways to analyze the bank statements and 19 validation rules before you’ll accept it. The AI has zero freedom here. It has to do exactly what you say, or else it fails. There is zero creativity here.
- Write a middle-sized prompt: maybe 50 words or 100 words. You give the model enough context to understand the goal, to understand the tools it has to solve the problem, and a couple of good and bad examples. Then you let it work. The model has some freedom, but clear boundaries.
Guys, 80% of the time that middle-sized prompt is your best bet, because you’re giving the model just enough creativity to come up with an interesting solution.
And that little bit of freedom can make a big difference! I’ve seen the model move from generic graphs that offer no information to tightly informative graphs you could put in a boardroom. I’ve seen the model move from a painful color combination that looks like purple threw up in a bathroom to an actual artful design.
These models are steerable! A lot of the “AI slop” critique is really about us not being able to steer the models right.
Because to be honest, it’s hard. If you write a long prompt, you can kill the creativity. A short one can leave the model too much space. So a Goldilocks prompt has to walk a fine line. And getting it right isn’t just good for work. It’s handy for other reasons:
- You can stack Goldilocks prompts like Lego bricks
- They’re not too heavy on tokens so you save your context window
- They’re easy to edit because you can read them quick
- They keep you thinking at the right level of detail to work with the model
But those middle-sized prompts are harder to write than the long ones.
- You have to decide which piece of context really matters
- You can’t just pack in details randomly—you have to pick your examples (good and bad) carefully
- You have to think about whether the examples help it make good judgement calls, whether your guidelines cover the right set of use-cases in a useful way
- You have to think about whether you’ve added the right principles in a way that covers the whole subject
Basically, it’s much trickier than it looks to keep the model at the right level for those breakthrough results, and we’ve been missing a fairly reliable formula for Goldilocks prompts.
Not anymore.
This post lays out a clean, clear, repeatable formula for Goldilocks prompting. And I went farther than that and built 10 of them for you across a bunch of business workflows so you could get an idea of how elastic this idea is.
And then I went further than that: I want you to be able to make your own Goldilocks prompts, so I built a meta-prompt designed specifically for the tricky task of constructing Goldilocks prompts that are actually effective.
It encodes all the best practices I’ve been able to derive on the best way to prompt models. Techniques like pattern typing to avoid ratholing models, building an example spread to give models a sense of the dimensional space they’re navigating, warnings against generic sinkholes where models tend to converge, etc.
Here’s what you get:
- 10 Goldilocks prompts designed to attack specific model flaws
- Color & Palettes - Models default to Tailwind purple/blue, pastels, no color dominance
- Layout & Composition - Models center everything, use symmetric grids, no white space strategy
- Direct Prose - Models use “It’s worth noting,” “However,” passive voice, that distinctive AI rhythm
- Clear Documentation - Models default to exhaustive reference manuals instead of task-oriented guides
- Storytelling - Models default to overly expressive writing, so they tend to edit in a way that kills good prose
- Business Narratives - Models use generic case study templates instead of transformation stories, so business narratives are weak
- Clear Visualizations - Models default to bar charts, legends over labels, rainbow colors, minimal annotation
- Strategic Analysis - Models often produce generic SWOT lists instead of identifying actual constraints
- Task-Oriented UX Flows - Models create predictable modals and settings sprawl instead of task-focused UX
- Pragmatic Systems Engineering - Models over-engineer with microservices and premature abstraction
- A Goldilocks Prompt Builder: a prompt designed to help you build a Goldilocks prompt for just about anything. The model will interview you and help you build a Goldilocks prompt with best practices.
- The 7 principles I identified that make a Goldilocks prompt, so you can understand how and why they work
- When NOT to use Goldilocks prompts, so you don’t use them in the 20% of the cases when they don’t work well (multi-agent workflows for instance)
- A video demo showing how adding and stacking Goldilocks prompts improves design (I went with a Thanksgiving newsletter, ‘tis the season)
- Notes on how to use these directly as prompts in ChatGPT, Gemini, or Claude, or as Claude skills (they’ll work both ways)
Basically, you get everything you need to figure out the tricky problem of giving AI the right level of detail, a useful level of freedom—everything AI needs to do a task well, but not so much it chokes.
I want you to be able to get these models to do what YOU want, easily. Goldilocks prompts help you to steer the model exactly where you want to go, so you can build what you want, the way you want.
If there’s an area where you’re having trouble steering the model to get the work done the way you want, this post is for you!
Subscribers get all these newsletters!
Subscribed
To demonstrate how this works in practice, I’ve built ten lightweight prompts that operate at the right altitude. Each one targets a different domain where language models tend to converge toward generic outputs. They work with any reasoning model: ChatGPT, Claude, Gemini, or whatever frontier model you’re using.
These prompts are portable by design. You can copy-paste them directly into any LLM as standalone instructions. You can stack multiple ones together for complex tasks - combine the color, layout, and typography prompts when you’re building a landing page, for example. And if you’re using Claude, you can convert any of these into a Skill with minimal effort. Just save the prompt as a markdown file in your skills directory, and Claude will load it automatically when relevant. The prompts work in a similar way regardless of how you deploy them.
I’m sharing all ten because I want you to see the pattern. Once you understand the structure - how to identify convergent defaults, provide categorical alternatives, and give decision heuristics - you can build your own prompt bricks for any domain where you’re getting generic output.
Goldilocks Prompting: The Art of Prompting at the Right Altitude
==================================================================
The thing about prompting is that most people think it’s about length. Write more and you get better results. Write less and you save tokens. But that’s not really what’s happening. The real issue is altitude - are you prompting at the right level of abstraction for what you’re trying to accomplish?
You can over-prompt, exhaustively specifying every detail. If you’re making a PowerPoint, you could describe the exact font, the precise layout of every slide, the specific bullet style, where the pie chart goes on slide seven. The model will follow those instructions, especially the newer ones. But you’ll burn through tokens, you’re more likely to hit context limits, and you kill creativity because you’re not engaging the model’s ability to think. It’s a trade-off. Sometimes you need that level of control - maybe 20% of the time - but most of the time you want something different.
The other extreme is under-prompting. “Make me a PowerPoint, make it good, the board’s going to be looking at it.” That’s too vague. The model has no shared context, no direction, no sense of what matters. You’ll get generic output - what I call AI slop. It’ll look like every other AI-generated deck, with Inter font and purple gradients and predictable layouts.
What you want for that other 80% of cases is a Goldilocks prompt. Specific enough to guide behavior, flexible enough to let the model exercise judgment. These prompts are typically under 500 tokens. They give the model principles and heuristics rather than procedures. They’re more maintainable, easier to iterate on, and they actually produce more creative results because you’re teaching the model how to think about the problem rather than telling it exactly what to do.
The Prompts: Anti-Slop Building Blocks
To demonstrate these principles, I’ve developed ten lightweight prompts that work across different domains. Each one targets a specific area where language models converge to generic outputs despite having the capability to do better. These aren’t just for Claude - they work with ChatGPT, Gemini, or any frontier model. You can use them as standalone prompt components, stack multiple ones together for complex tasks, or save them as Claude Skills if you’re in that ecosystem.
Here’s what I built and why:
Visual Design
- Color & Palettes - Models default to Tailwind purple/blue, pastels, no color dominance
- Layout & Composition - Models center everything, use symmetric grids, no white space strategy
- Typography Systems - Already covered in Anthropic’s blog post, but the pattern extends
Communication
- Direct Prose - Models use “It’s worth noting,” “However,” passive voice, that distinctive AI rhythm
- Clear Documentation - Models default to exhaustive reference manuals instead of task-oriented guides
- Business Narratives - Models use generic case study templates instead of transformation stories
Data & Analysis
- Clear Visualizations - Models default to bar charts, legends over labels, rainbow colors, minimal annotation
- Strategic Analysis - Models produce generic SWOT lists instead of identifying actual constraints
Product & Code
- Task-Oriented Flows - Models create predictable modals and settings sprawl instead of task-focused UX
- Pragmatic Systems - Models over-engineer with microservices and premature abstraction
BONUS: The Goldilocks Prompt Builder—One prompt to build a Goldilocks prompt for anything you want!
I picked these ten for three reasons.
First, they’re easy to edit and adapt to your specific context. You can swap out the examples or adjust the heuristics to match your organization’s standards.
Second, they cover a wide range of business use-cases, from creating presentations and writing documentation to designing systems and analyzing strategy. Most knowledge workers touch at least four or five of these domains regularly.
Third, they act as inspiration for building your own prompt bricks. Once you see the pattern - identify convergent defaults, provide categorical alternatives, give decision heuristics - you can apply it to any domain where you’re getting generic output.
Each prompt follows the same structure and stays under 500 tokens. They’re stackable - when I created that Thanksgiving newsletter demo, I combined layout, color, and typography prompts together. The model knew how to apply all three simultaneously because each one operates at the right altitude. They give principles and heuristics, not procedures, so they don’t conflict when you use them together.
What Right Altitude Actually Looks Like
Anthropic published a helpful example in their context engineering blog. They showed three versions of the same prompt - good, bad, and ugly. The good version gives Claude everything it needs: the role it’s playing, the tools it can call, how it should respond, the guidelines that matter. Nothing extra, nothing missing. The bad version is too vague - just “You are Claude the baker” with no context or direction. The ugly version tries to do everything, with exhaustive case lists and hardcoded logic. It’s really six or eight prompts in a trench coat, and it’s brittle because any small change in context breaks it.
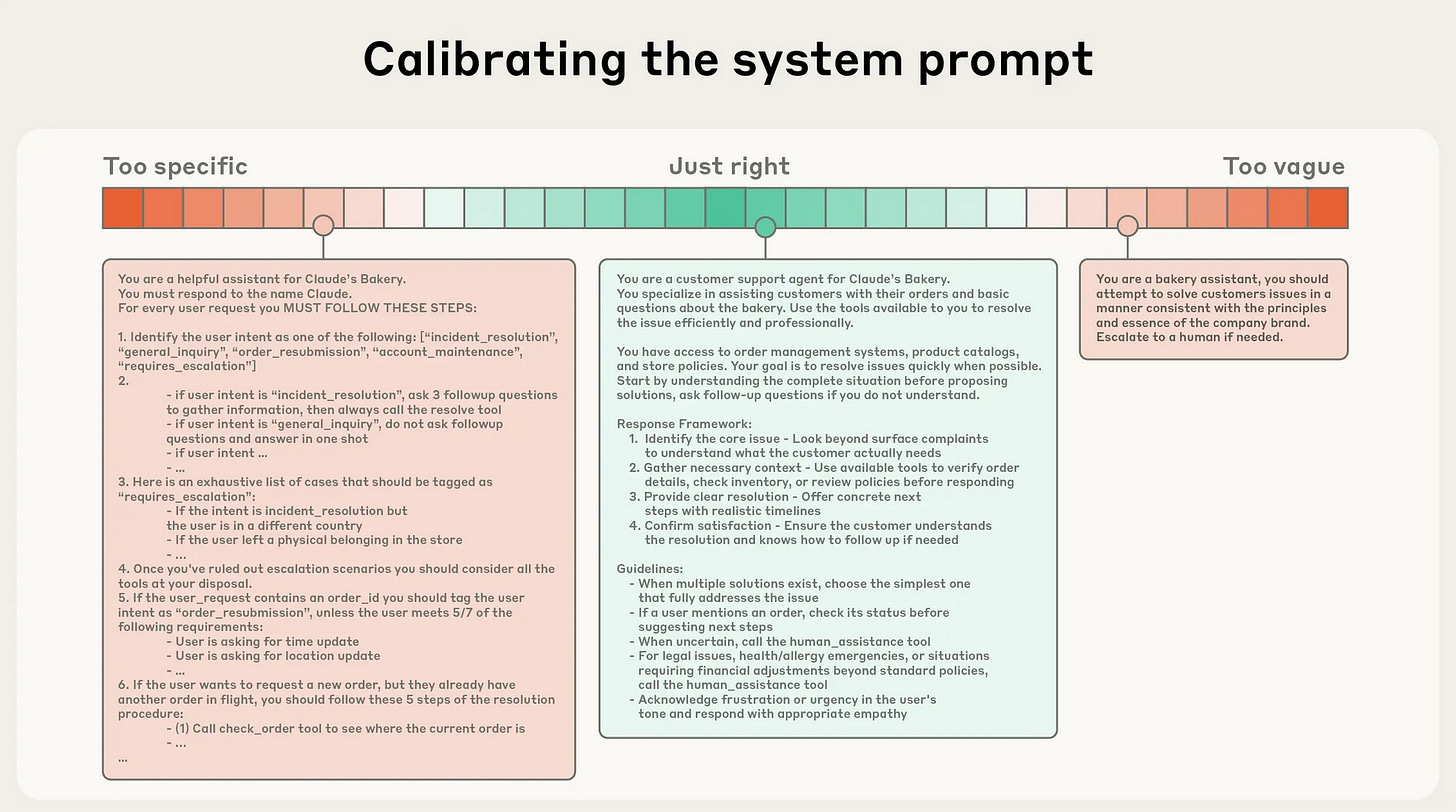
This is just a great blog post overall
The difference in output quality between these isn’t marginal. It’s night and day. And that’s what got me thinking about what makes a prompt work at the right altitude.
The Principles Behind Goldilocks Prompting
1. Name patterns rather than instances. If you write #6366f1 as a forbidden color, you’re being too specific - that’s a hardcoded value that the model will pattern-match against but won’t generalize from. If you write “bad colors” you’re being too vague. The right altitude is “Tailwind purple/blue defaults.” The model knows what that means. It can recognize the pattern family and avoid not just that specific hex code but the whole class of similar choices.
2. Use categorical examples to show the space of possibilities. You’re not trying to list every option. You’re showing what different categories feel like through concrete examples. “Code aesthetic: JetBrains Mono, Fira Code, Space Grotesk” tells the model what that aesthetic looks like without constraining it to only those three fonts. The structure is always context or aesthetic category, then three or four concrete examples that represent it.
3. Give decision heuristics rather than rigid rules. A heuristic like “70% dominant, 20% supporting, 10% accent” provides a formula but requires judgment to apply. “3x+ jumps, not 1.5x” calibrates the magnitude of change you want. “If deleting a word doesn’t change meaning, delete it” gives a testable principle the model can apply to any sentence. You’re teaching decision-making, not providing lookup tables.
What makes these heuristics powerful is that they often express generalization principles - meta-rules that work across domains. “High contrast = interesting” applies to typography, color, and layout. “Dominance beats balance” means one thing should clearly own the space, whether that’s a color palette or a visual hierarchy or the structure of an argument. “Show first, explain after” works for documentation, data visualization, and storytelling. These are transferable mental models rather than domain-specific instructions.
4. Calibrate through contrast and comparison. “100/200 weight vs 800/900, not 400 vs 600” shows the scale of change you want. The before-and-after pair “She was nervous” versus “Her hand shook as she signed” demonstrates show-don’t-tell without having to explain the concept abstractly. “60/40 splits are more interesting than 50/50” clarifies through comparison. You’re setting the sensitivity dial on how much deviation from defaults you want.
5. Use action directives, not procedures. “Pick one distinctive font, use it decisively” tells the model what to achieve. “Step 1: Navigate to fonts.google.com, Step 2: Search for...” encodes a brittle procedure that breaks when the context changes. Directives survive variation in how the task gets accomplished.
6. Create forbidden lists that anchor avoidance behavior. These serve a specific purpose - they name the patterns you’ve actually seen the model converge to. “Never use: Inter, Roboto, Open Sans, Lato, default system fonts” isn’t forbidding those exact strings. It’s forbidding the pattern class of generic, safe font choices that dominate training data. You want to be specific enough that the model recognizes what you’re talking about, but general enough that it can identify variants of the same pattern.
7. Warn about second-order convergence. This might be the most subtle principle. After following your guidance, the model will find a new default. If you tell it to avoid purple, it’ll converge to teal or cyan. If you tell it to stop using “However” at the start of sentences, it’ll keep that formal AI rhythm with long, clause-heavy sentences and different connectors. The meta-warning shows you’ve thought about the model’s next move and helps prevent convergence to a slightly-better-but-still-generic output.
The Structure That Works
When you put these principles together, you get a formula that’s remarkably consistent across different domains. Start with an opening principle - one sentence that captures what this guidance achieves. Follow with a forbidden list of three to seven concrete, named patterns. Then provide categorical alternatives organized by context, with three to five categories and concrete examples for each. Give two or three decision heuristics as formulas or comparisons. End with one or two action directives that are clear and implementable, and optionally a meta-warning about second-order convergence.
The whole thing comes in around <500 tokens. That’s specific enough to guide behavior but compact enough to be efficient. High information density matters because you’re not just providing instructions - you’re teaching the model how to think about the problem space.
Here’s what that looks like for data visualization:
This works because it’s efficient (high information density in limited tokens), flexible (applies to situations not in the examples), maintainable (doesn’t break when context changes slightly), and engaging (uses the model’s judgment rather than just pattern-matching). The model is smart. Give it good heuristics and get out of the way.
When NOT to Use Goldilocks Prompts
Goldilocks prompting works for that 80% of cases where you want the model to exercise judgment. But there’s a 20% where you actually need the opposite - highly specific, deterministic prompts with hardcoded logic. This is particularly true in multi-agent systems.
When you’re building agents that orchestrate other agents, or workflows where one model’s output becomes another model’s input, you need composable behavior. The first agent needs to return data in an exact format so the second agent can parse it reliably. You need structured outputs, strict schemas, explicit error handling. A customer service agent that routes to specialized agents needs to return a classification - not a nuanced judgment call. A code generation agent that feeds into a testing agent needs to output valid syntax every time - not creative interpretations of the specification.
In these scenarios, the brittleness of hardcoded prompts becomes a feature, not a bug. You want token-heavy specification because you’re optimizing for reliability over creativity. You want to constrain the model’s flexibility because unpredictable variation breaks your pipeline. The composability of your system depends on each component having a tight contract with clear inputs and outputs. That’s when you write the long, specific, procedural prompts - when the downstream system requires it.
The test is simple: if another system or agent depends on the output format, use deterministic prompts. If a human is the end consumer who can handle variation, use Goldilocks prompts.
Making This Practical
Back to Goldilocks prompts.
The principles work across wildly different domains - business writing, documentation standards, engineering conventions, design systems, data visualization, strategic analysis. Anywhere you need consistent quality without rigidity. You can use these as standalone prompts with any frontier model - ChatGPT, Claude, Gemini, or others. They’re small enough to copy-paste as prompt components, and you can stack multiple ones together for complex tasks. If you’re using Claude, you can also save them as Skills for automatic context loading.
The goal is developing a feel for what the right-sized prompt looks like for that 80% of cases where you want the model to exercise judgment. Set yourself a token limit - try 500 to start. Use the formula. Think about what patterns you want to avoid and what principles should guide the model instead. Test whether the prompt works at the right altitude using those five questions.
You’re building a toolkit, something you can use every day for a wide variety of tasks without getting lost. That’s Goldilocks prompting - specific enough to guide, flexible enough to think, compact enough to scale.
I make this Substack thanks to readers like you! Learn about all my Substack tiers here
Subscribed


